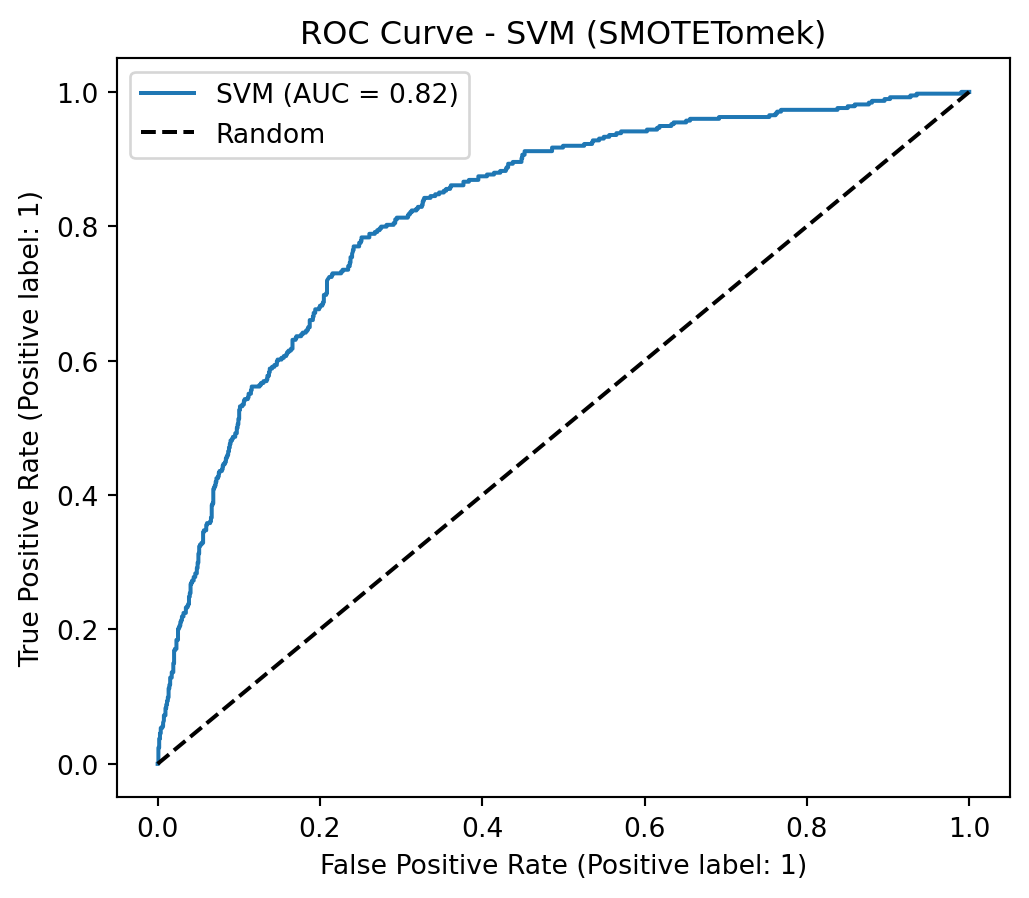
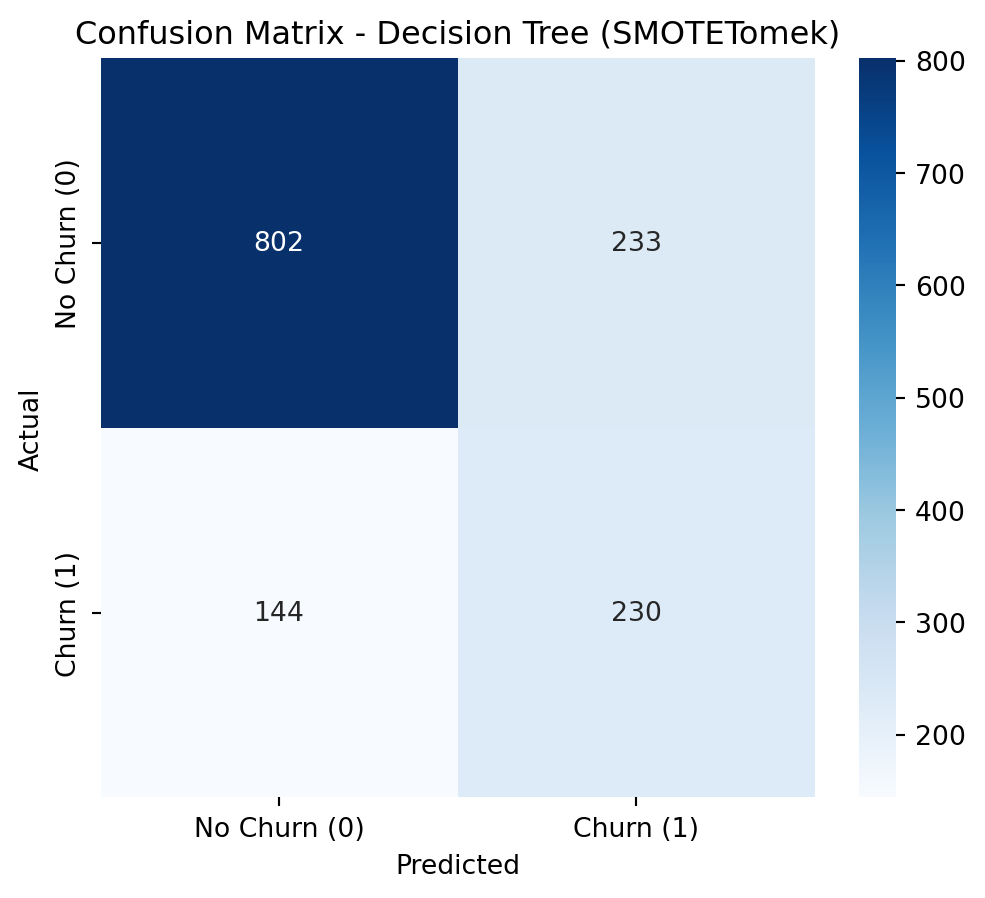
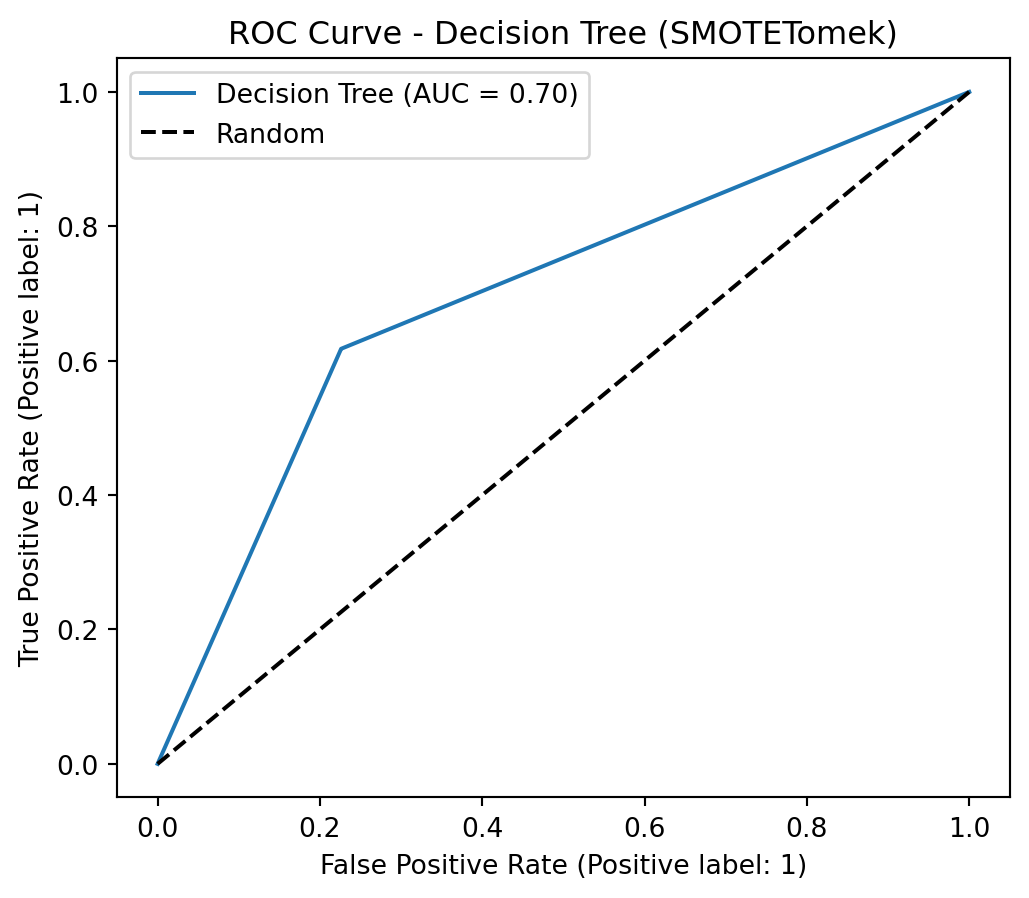
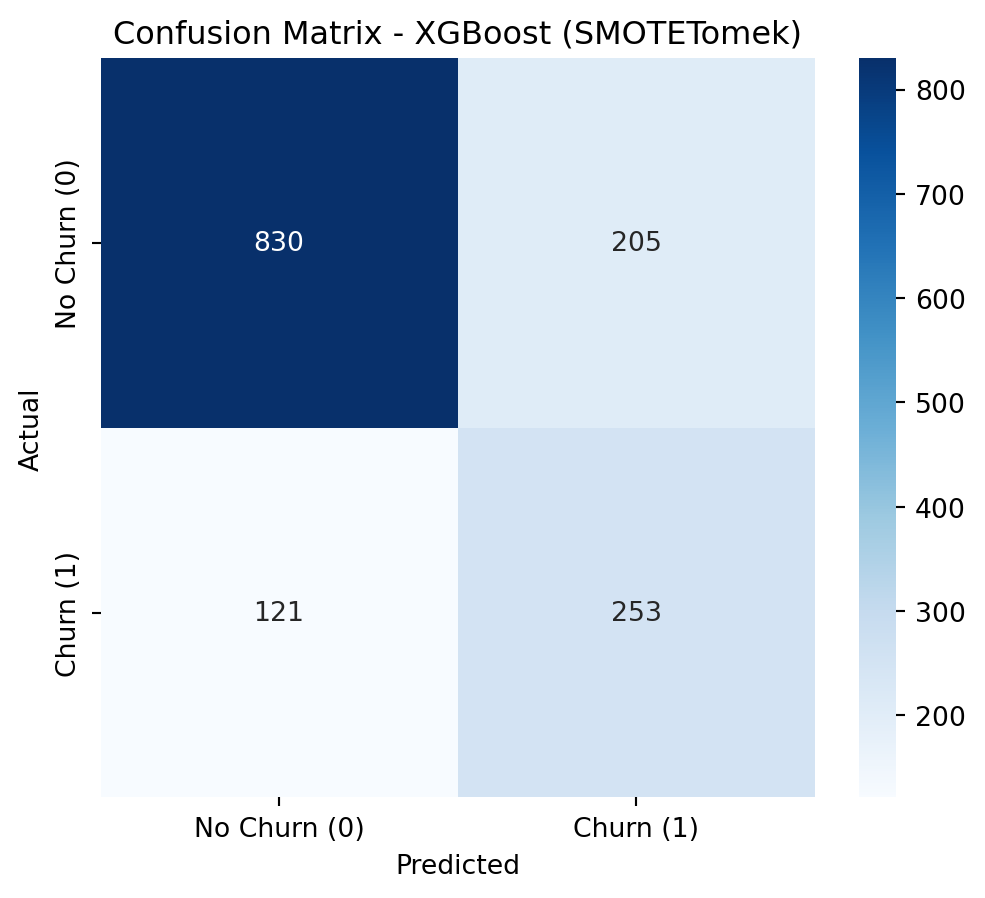
The objective of this project is to analyze and build a Machine Learning model based on customer churn data. The dataset contains information about a fictional telecommunications company that provided landline phone and internet services to 7,043 customers in California in the third quarter. It indicates which customers left, stayed, or signed up for their service. Churn prediction identifies customers who are likely to cancel their contracts soon. If the company can do this, it can address the users before churn.
The target variable we want to predict is categorical and has only two possible outcomes: churn or non-churn (Binary Classification). We would also like to understand why the model thinks our customers are leaving, and for that, we need to be able to interpret the model’s predictions. According to the description, this dataset contains the following information:
Customer services: phone; multiple lines; internet; tech support and extra services, such as online security, backup, device protection, and TV streaming
Account information: how long they’ve been a customer, contract type, payment method type
Charges: how much was charged to the customer last month and in total
Demographic information: gender, age, and whether they have dependents or a partner
Churn: yes/no, whether the customer left the company last month
Project Structure
The development of this project followed a structured and iterative methodology, covering everything from data collection and preparation to the evaluation and interpretation of results.
The TotalCharges column has 11 missing values. Let’s analyze it to define the best strategy to handle them.
Displaying the Full Rows with Missing Value:
Show Code
df[df['TotalCharges'].isna()]
customerID
gender
SeniorCitizen
Partner
Dependents
tenure
PhoneService
MultipleLines
InternetService
OnlineSecurity
...
DeviceProtection
TechSupport
StreamingTV
StreamingMovies
Contract
PaperlessBilling
PaymentMethod
MonthlyCharges
TotalCharges
Churn
488
4472-LVYGI
Female
0
Yes
Yes
0
No
No phone service
DSL
Yes
...
Yes
Yes
Yes
No
Two year
Yes
Bank transfer (automatic)
52.55
NaN
No
753
3115-CZMZD
Male
0
No
Yes
0
Yes
No
No
No internet service
...
No internet service
No internet service
No internet service
No internet service
Two year
No
Mailed check
20.25
NaN
No
936
5709-LVOEQ
Female
0
Yes
Yes
0
Yes
No
DSL
Yes
...
Yes
No
Yes
Yes
Two year
No
Mailed check
80.85
NaN
No
1082
4367-NUYAO
Male
0
Yes
Yes
0
Yes
Yes
No
No internet service
...
No internet service
No internet service
No internet service
No internet service
Two year
No
Mailed check
25.75
NaN
No
1340
1371-DWPAZ
Female
0
Yes
Yes
0
No
No phone service
DSL
Yes
...
Yes
Yes
Yes
No
Two year
No
Credit card (automatic)
56.05
NaN
No
3331
7644-OMVMY
Male
0
Yes
Yes
0
Yes
No
No
No internet service
...
No internet service
No internet service
No internet service
No internet service
Two year
No
Mailed check
19.85
NaN
No
3826
3213-VVOLG
Male
0
Yes
Yes
0
Yes
Yes
No
No internet service
...
No internet service
No internet service
No internet service
No internet service
Two year
No
Mailed check
25.35
NaN
No
4380
2520-SGTTA
Female
0
Yes
Yes
0
Yes
No
No
No internet service
...
No internet service
No internet service
No internet service
No internet service
Two year
No
Mailed check
20.00
NaN
No
5218
2923-ARZLG
Male
0
Yes
Yes
0
Yes
No
No
No internet service
...
No internet service
No internet service
No internet service
No internet service
One year
Yes
Mailed check
19.70
NaN
No
6670
4075-WKNIU
Female
0
Yes
Yes
0
Yes
Yes
DSL
No
...
Yes
Yes
Yes
No
Two year
No
Mailed check
73.35
NaN
No
6754
2775-SEFEE
Male
0
No
Yes
0
Yes
Yes
DSL
Yes
...
No
Yes
No
No
Two year
Yes
Bank transfer (automatic)
61.90
NaN
No
11 rows × 21 columns
We observe that the rows with missing TotalCharges have a tenure of 0. This means they are new customers who haven’t accumulated any charges yet. Therefore, we will impute these missing values with 0.
We are going to replace ‘No internet service’ and ‘No phone service’ with ‘No’. This is because they carry the same meaning (the customer does not have that particular service), and keeping them as separate categories would create unnecessary features without adding relevant information for the model.
Replacing these values with “No” across the DataFrame:
Show Code
valores_substituir = ["No internet service", "No phone service"]df = df.replace(valores_substituir, "No")
Let’s analyze the churn rate across our categorical variables, comparing the rate for each category against the global average churn rate
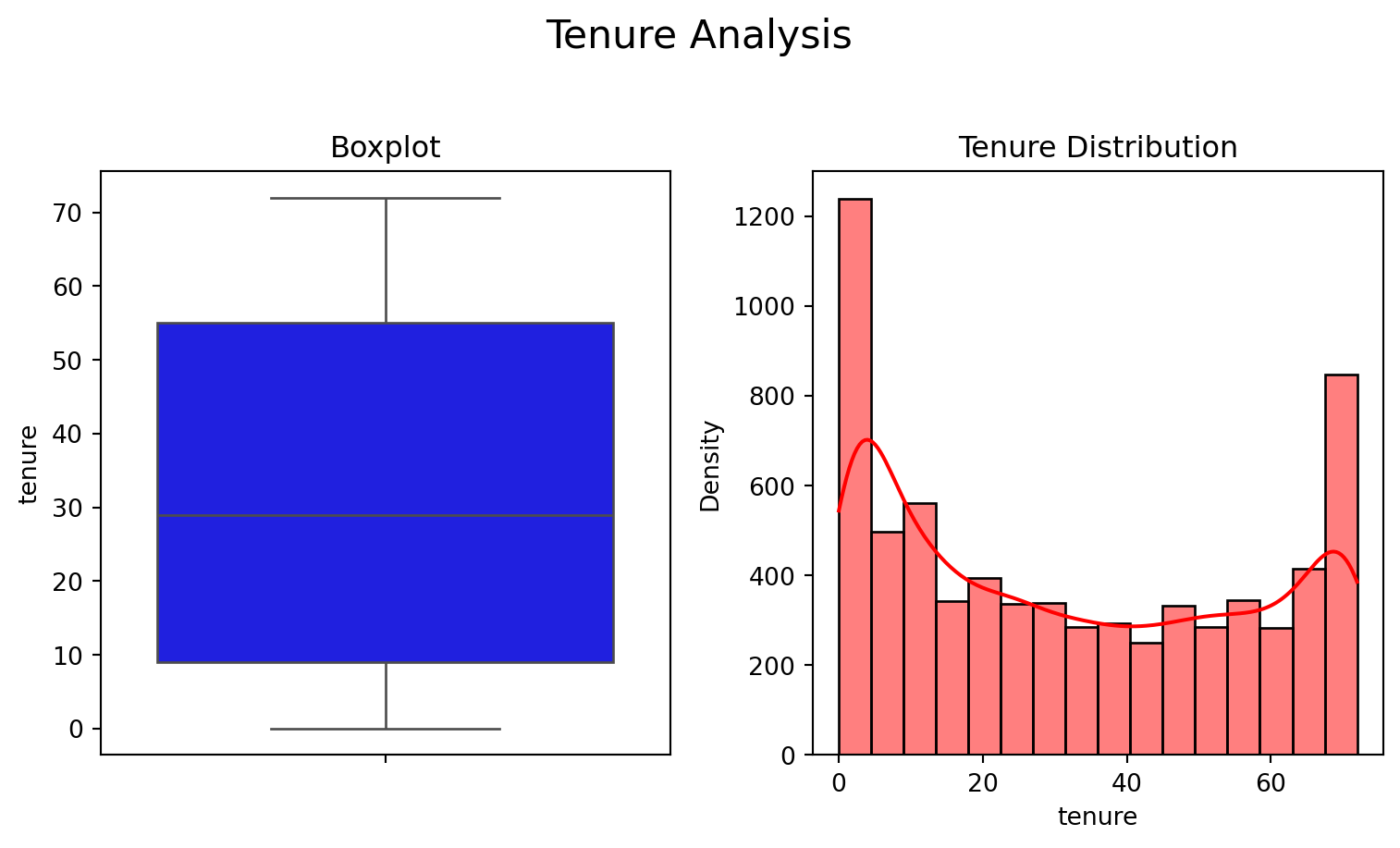
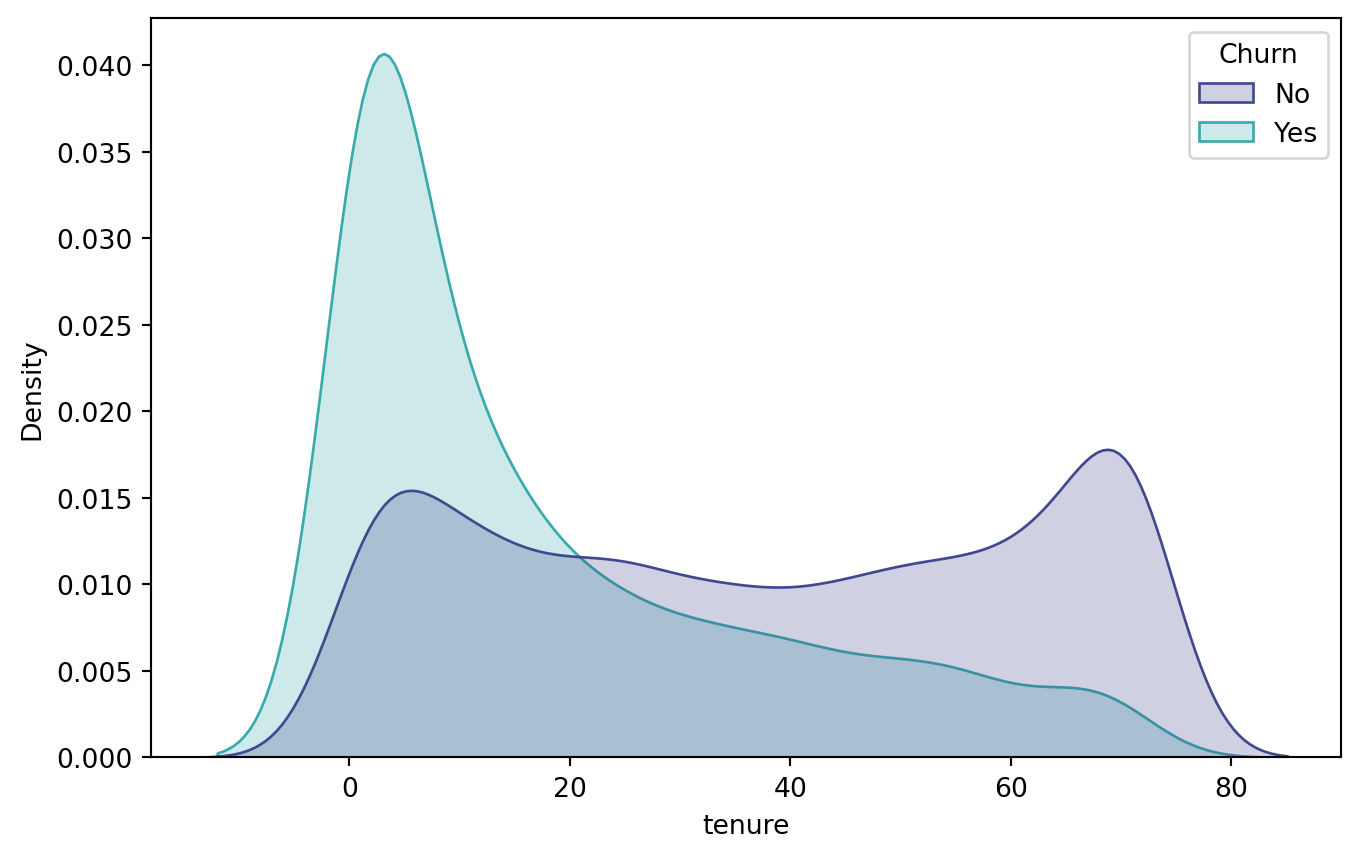
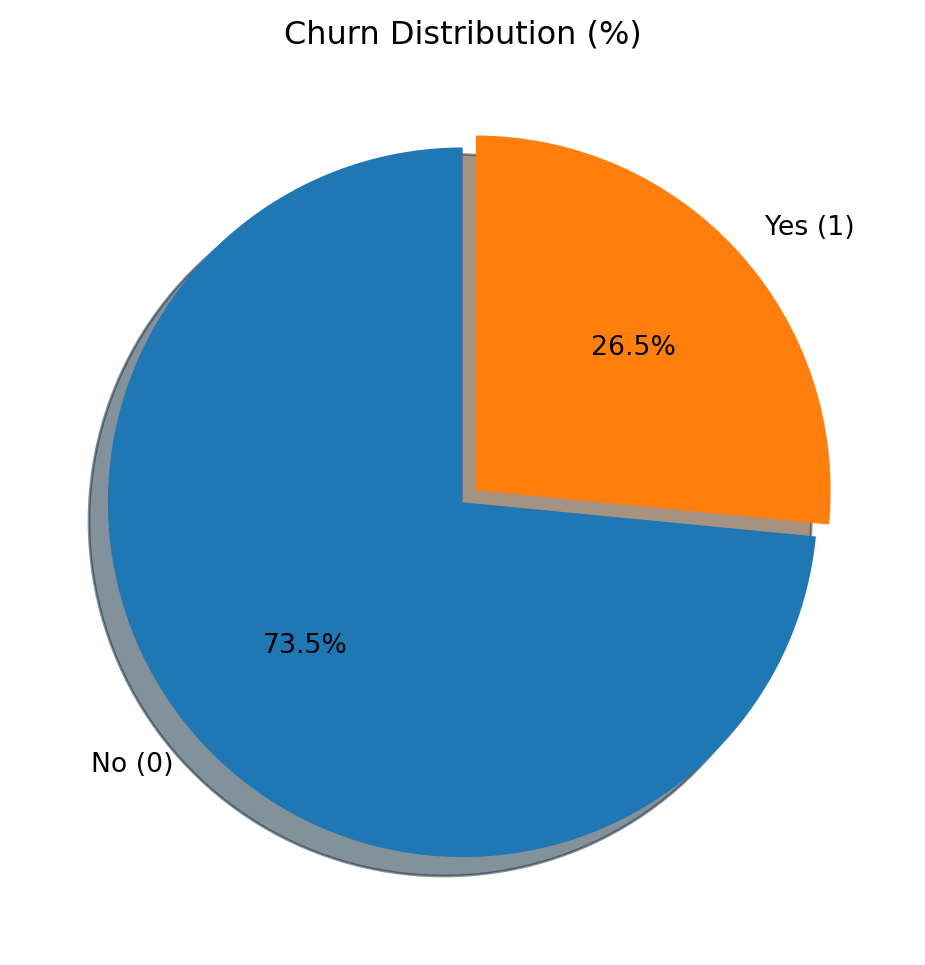
The average churn rate found in the dataset is approximately 27%, meaning that roughly one in every four customers terminates their contract. This is a significant rate and should be treated as a critical retention indicator. An analysis of the tenure variable shows a median of 29 months, but with 25% of customers staying for nine months or less, revealing a high concentration of short-term customers and suggesting that early churn is a primary risk.
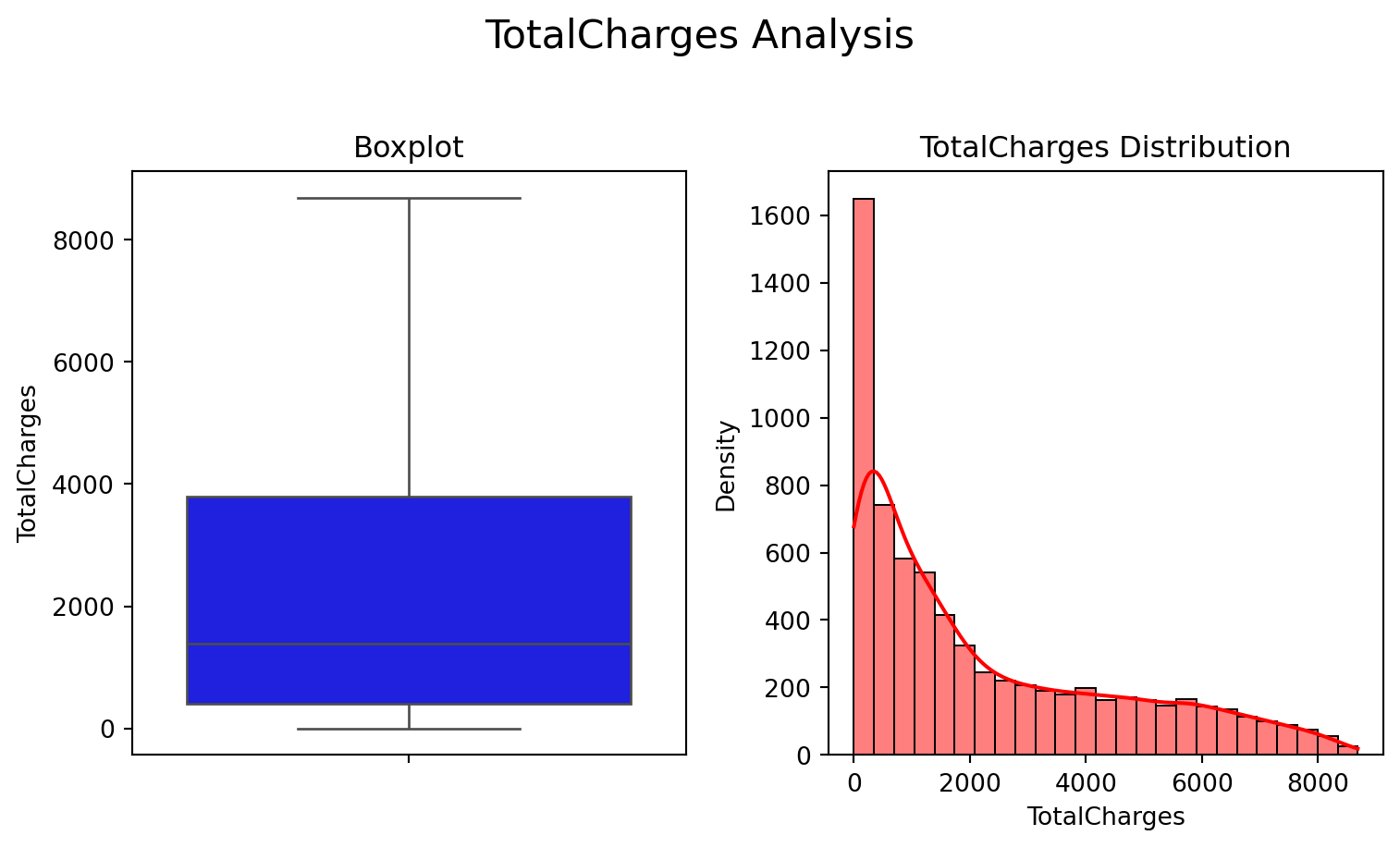
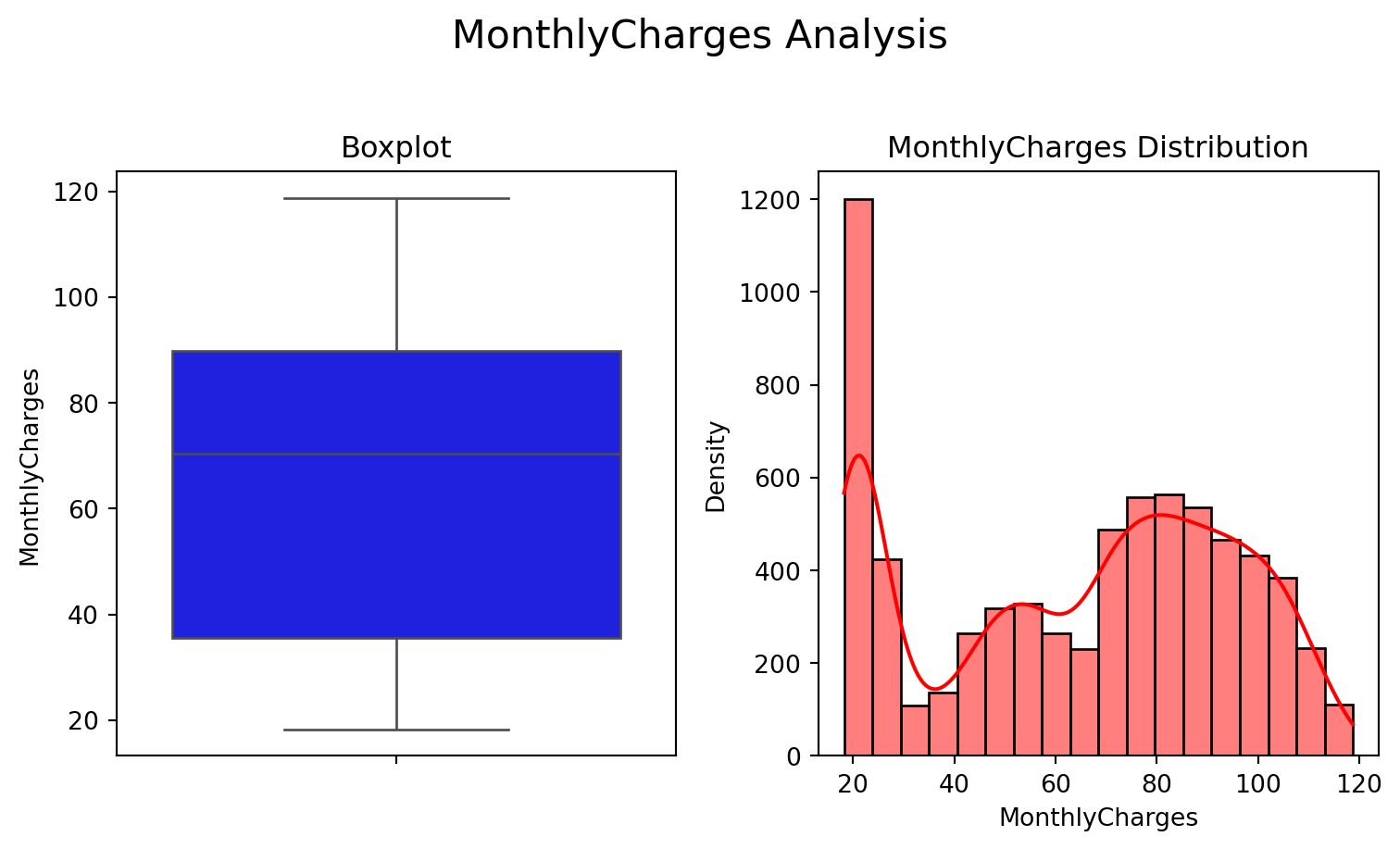
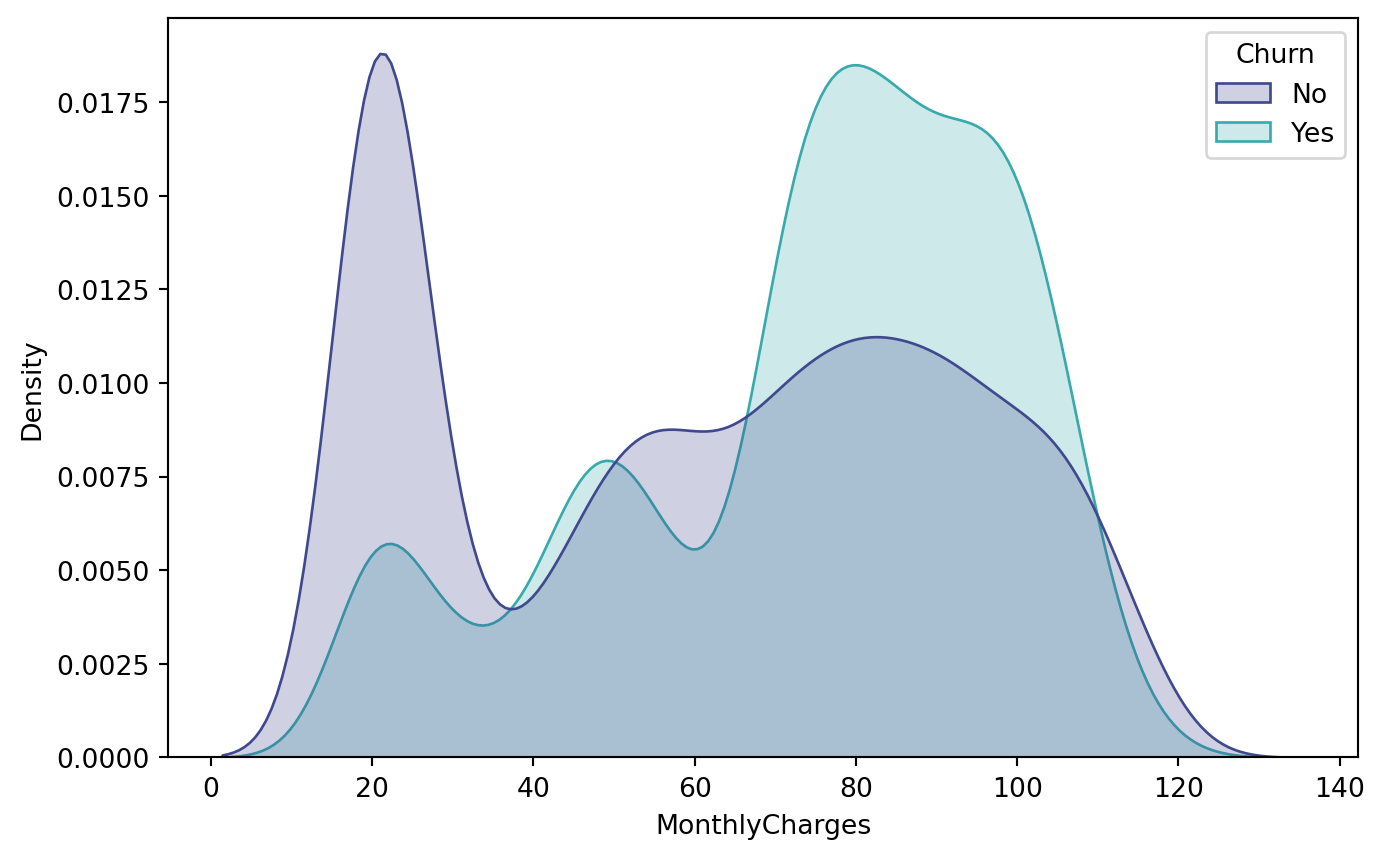
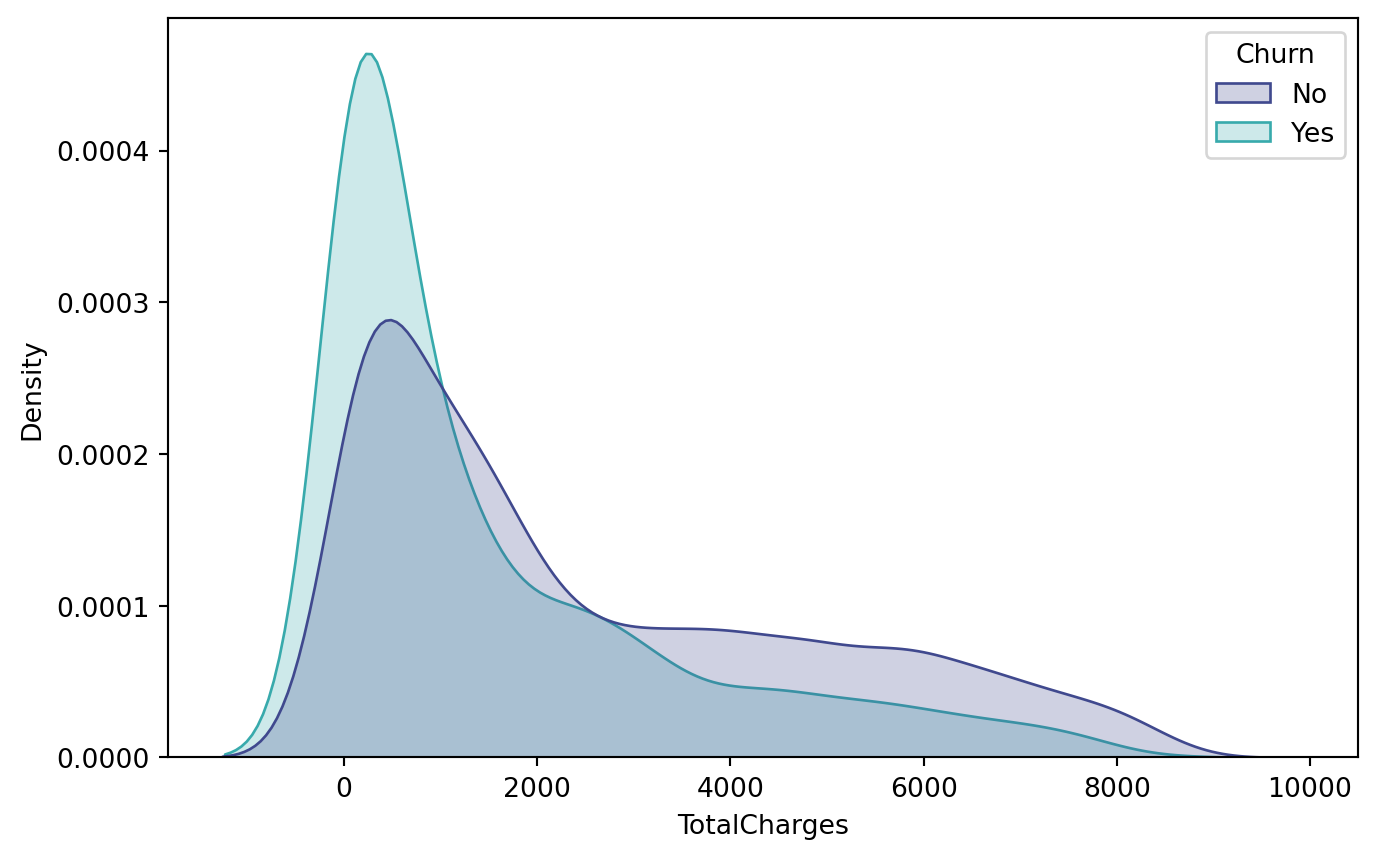
Regarding billing, the MonthlyCharges variable has a mean of around 64.8 but with a wide spread, indicating highly distinct consumption profiles. TotalCharges, in turn, reflects both the variation in contract length and the accumulation of spending over time.
Observing the categorical variables, it’s notable that customers on month-to-month contracts, those who use paperless billing, and those with certain payment methods exhibit churn rates higher than the global average. These profiles, therefore, constitute strategic targets for targeted interventions. It is also worth highlighting that the data handling applied to TotalCharges was essential to prevent distortions and ensure consistency in the comparisons made.
The relationship between churn and tenure reveals that customers who cancel tend to be concentrated in the first few months of their contract, reinforcing the need for specific onboarding and loyalty strategies in the very first cycles. The comparison between churn and MonthlyCharges indicates that there are billing ranges in which the propensity to cancel is higher, especially among customers with higher invoice values, which suggests a need to evaluate the perceived cost-benefit in this segment.
Data Preprocessing
Dropping the customerID column as it has no predictive value:
Show Code
df = df.drop('customerID', axis=1)
Describe current df:
Show Code
df.describe(include=['object', 'bool'])
gender
Partner
Dependents
PhoneService
MultipleLines
InternetService
OnlineSecurity
OnlineBackup
DeviceProtection
TechSupport
StreamingTV
StreamingMovies
Contract
PaperlessBilling
PaymentMethod
Churn
count
7043
7043
7043
7043
7043
7043
7043
7043
7043
7043
7043
7043
7043
7043
7043
7043
unique
2
2
2
2
2
3
2
2
2
2
2
2
3
2
4
2
top
Male
No
No
Yes
No
Fiber optic
No
No
No
No
No
No
Month-to-month
Yes
Electronic check
No
freq
3555
3641
4933
6361
4072
3096
5024
4614
4621
4999
4336
4311
3875
4171
2365
5174
Label Encoding for binary variables:
Show Code
binarias = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines','OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport','StreamingTV', 'StreamingMovies', 'PaperlessBilling', 'Churn']# Mapping Yes/No to 1/0 and Male/Female to 1/0mapeamento = {'Yes': 1,'No': 0,'Male': 1,'Female': 0}for col in binarias: df[col] = df[col].map(mapeamento)
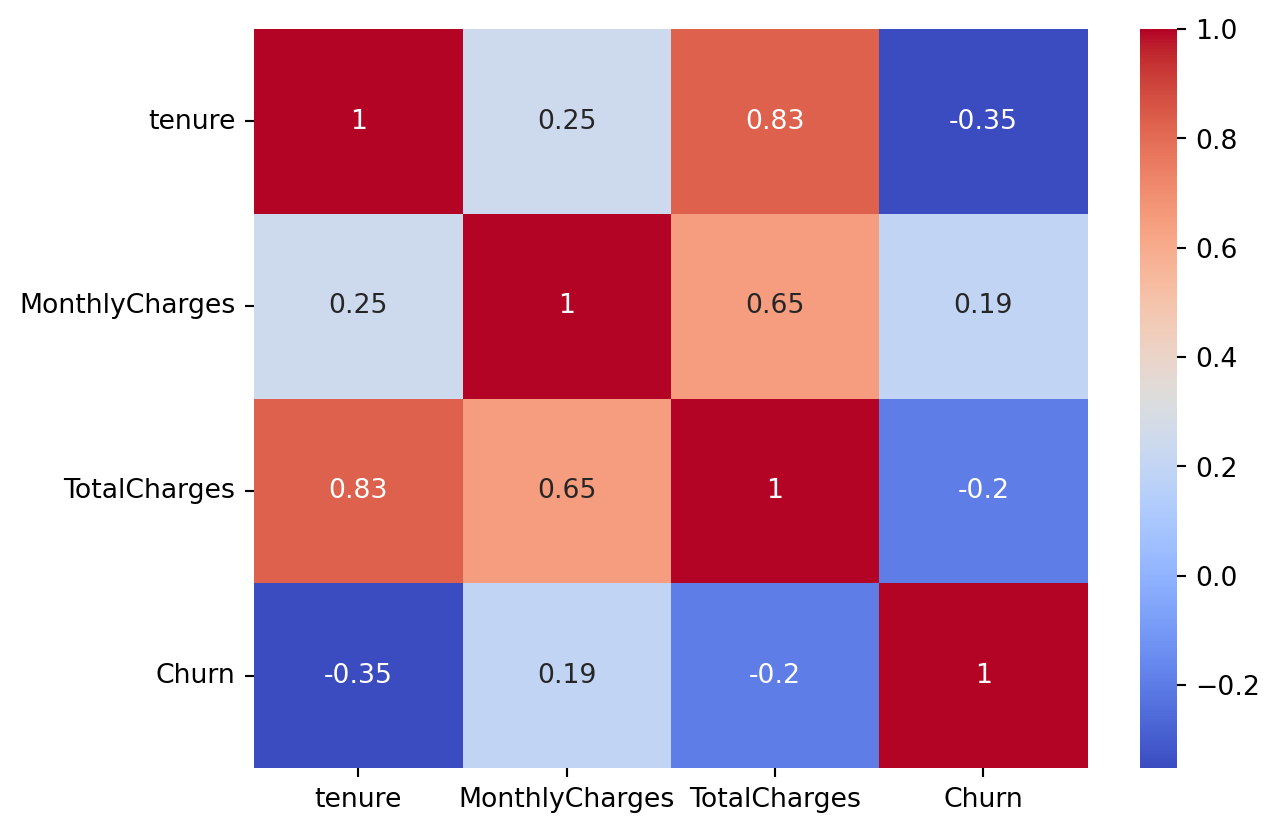
The 0.826 correlation between tenure and TotalCharges is extremely high, indicating strong multicollinearity. TotalCharges is fundamentally the product of tenure and MonthlyCharges (or, more precisely, the sum of MonthlyCharges over the tenure). Keeping all three variables together would add redundancy and could complicate interpretability, especially for linear models, without necessarily adding more predictive power.
We opted to remove TotalCharges, as we still retain crucial information from tenure (the customer’s length of stay, a key indicator of loyalty and maturity) and MonthlyCharges (the current cost of service, which correlates with the quality/service package and is a strong predictor of churn). Together, these two variables already capture the essence of what TotalCharges represents.
The other strong correlations reflect the intrinsic business relationship between the service value (MonthlyCharges) and the service type (InternetService). Removing either of these variables would mean losing valuable information about the customer’s service package, which is a very strong predictor of churn. The Machine Learning model can and should use this information to learn the relationship. The multicollinearity here is more of a reflection that one variable (MonthlyCharges) is heavily influenced by another (InternetService), and both are relevant.
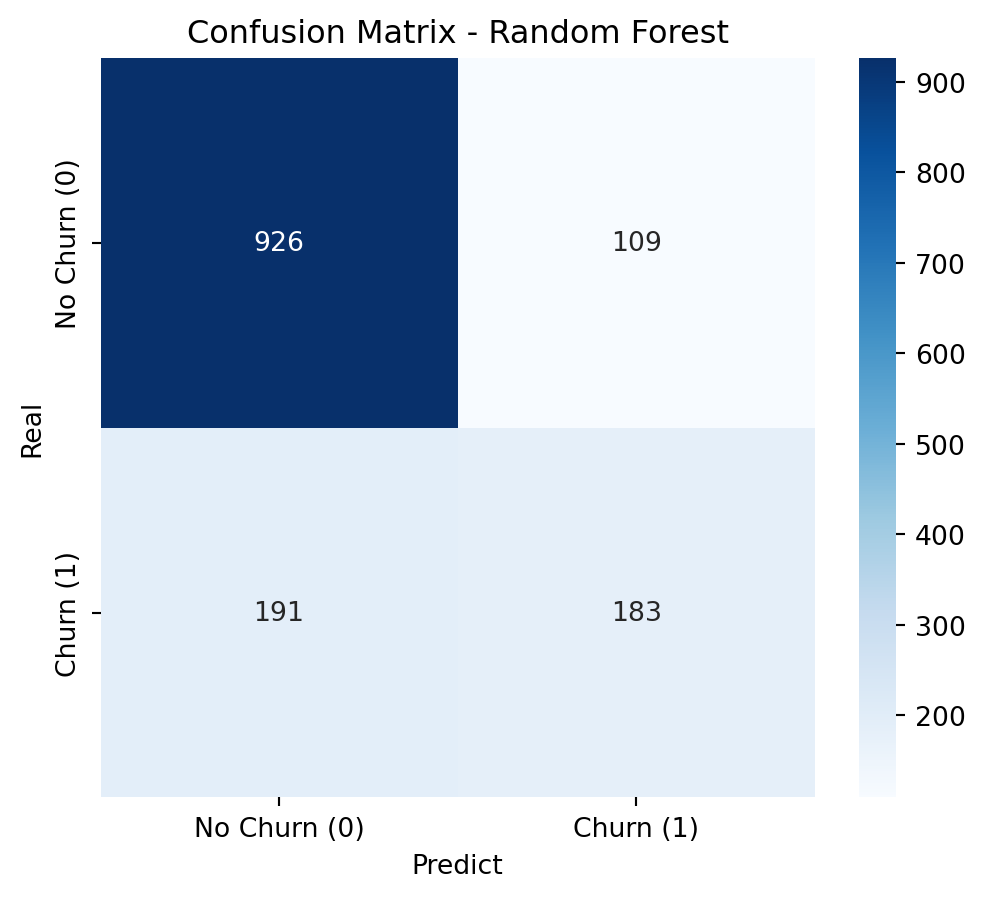
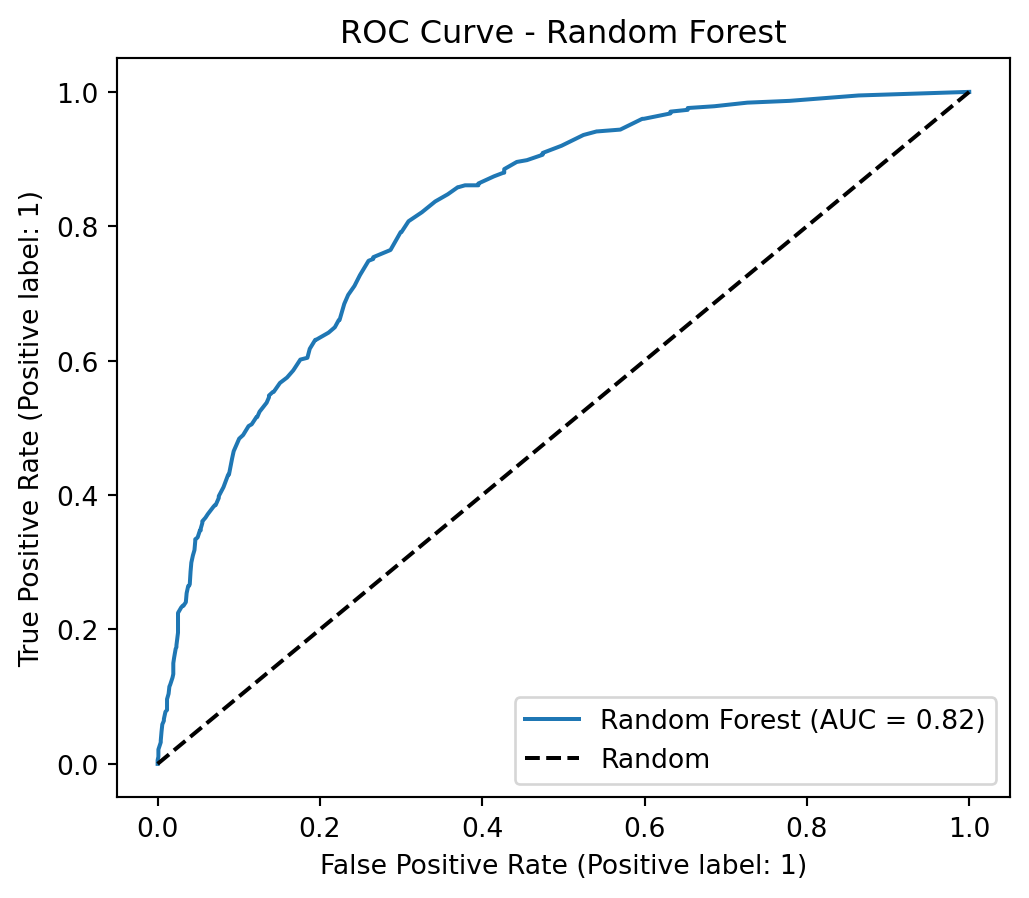
We are facing a class imbalance problem in our target variable. To address this, we will test different strategies and approaches to determine which one yields the best model. Our objective is to build a model with an accuracy above 80%.
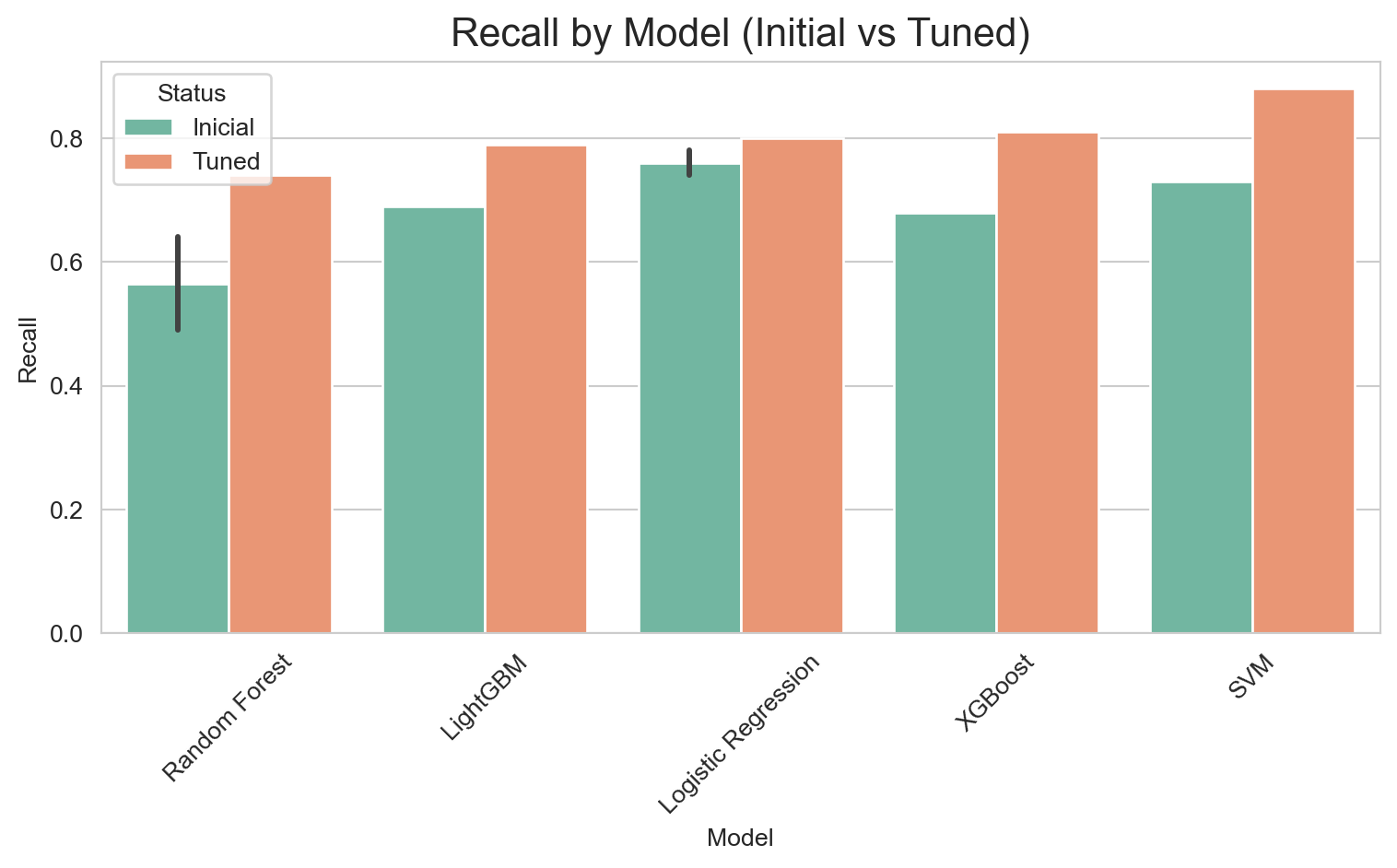
Why Recall? In the context of customer churn prediction, Recall (also known as Sensitivity or True Positive Rate) is the primary metric to optimize. It measures our model’s ability to correctly identify the highest possible proportion of customers who will actually leave the company (the “Churn” minority class).
Minimizing Customer Losses (False Negatives): The cost of a False Negative (a customer the model predicted would not churn, but who actually did) is typically very high for a business. Each lost customer represents not only the interruption of future revenue but also the potential loss of Lifetime Value (LTV), the costs of acquiring new customers, and a negative impact on reputation. A high Recall means we are minimizing these False Negatives, ensuring that most customers at risk of churning are flagged for intervention.
Opportunity for Proactive Intervention: By identifying a customer with a high probability of churning (thanks to a high Recall), the company gains the opportunity to implement targeted retention strategies (personalized offers, proactive support, satisfaction surveys). Missing this opportunity due to a False Negative is the most costly error in this scenario.
Although Recall is the priority, we do not disregard Precision, F1-Score, and AUC-ROC:
In summary, our focus is to ensure that the largest possible number of at-risk customers are identified (high Recall), enabling effective retention actions. The other metrics help us refine the model, ensuring that these interventions are as efficient and targeted as possible, thus optimizing the return on investment (ROI) in churn prevention.
Separating Features (X) and Target Variable (y):
Show Code
X = df.drop('Churn', axis=1)y = df['Churn']
Splitting data into train and test:
Show Code
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
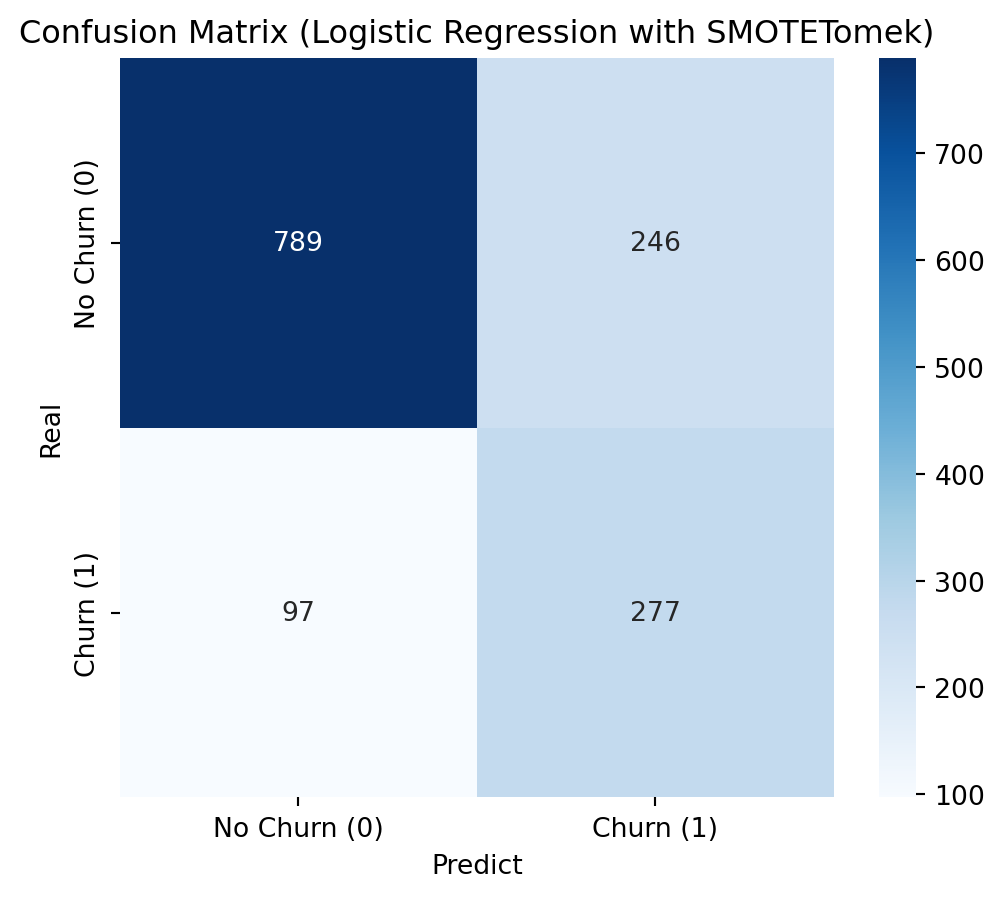
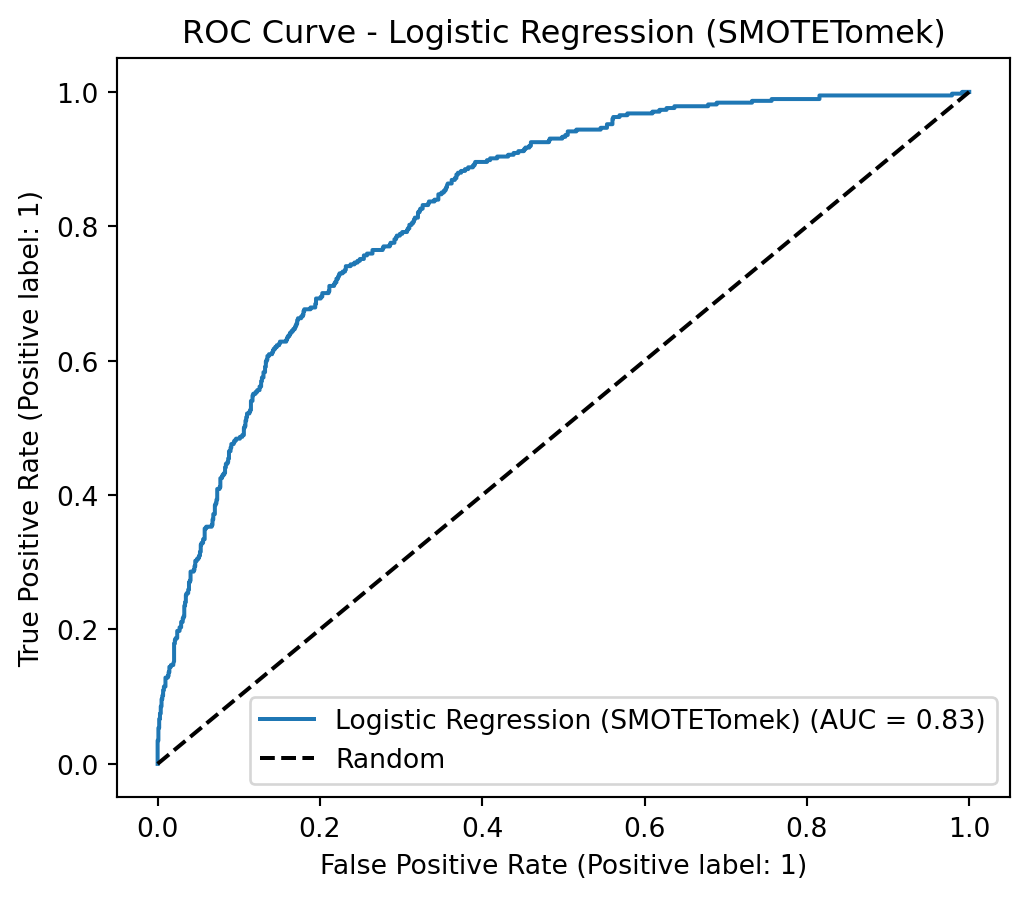
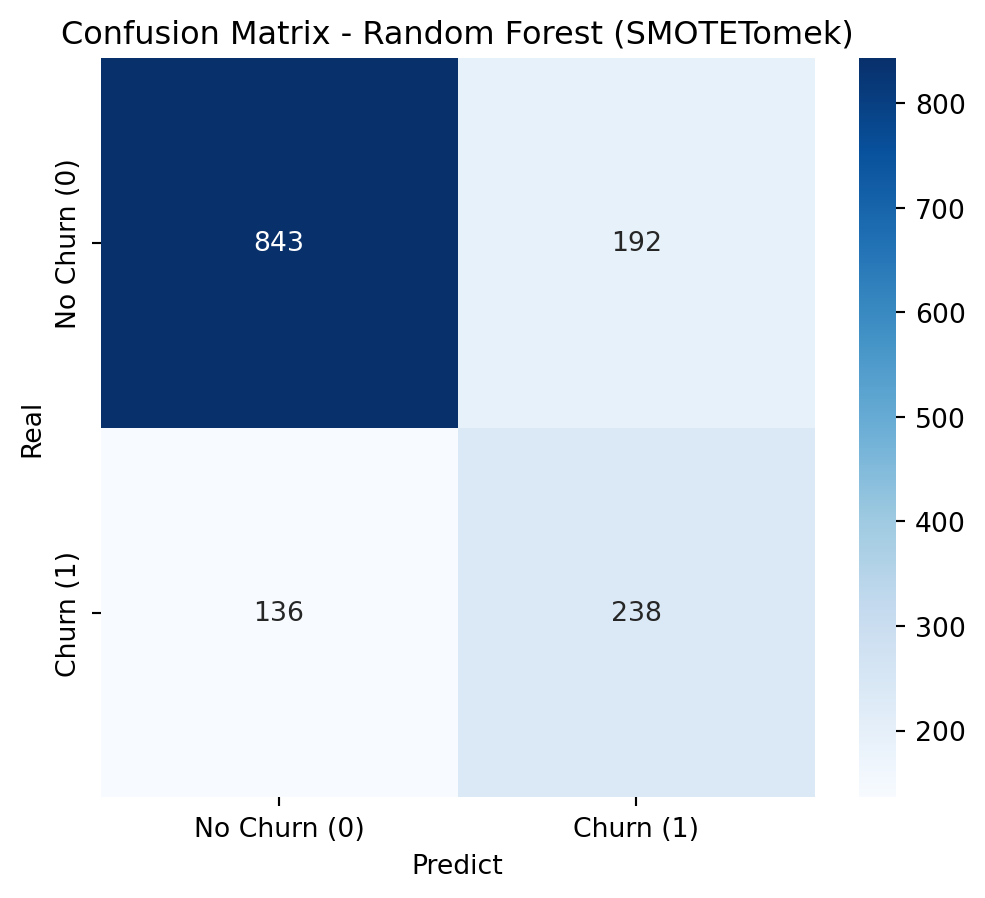
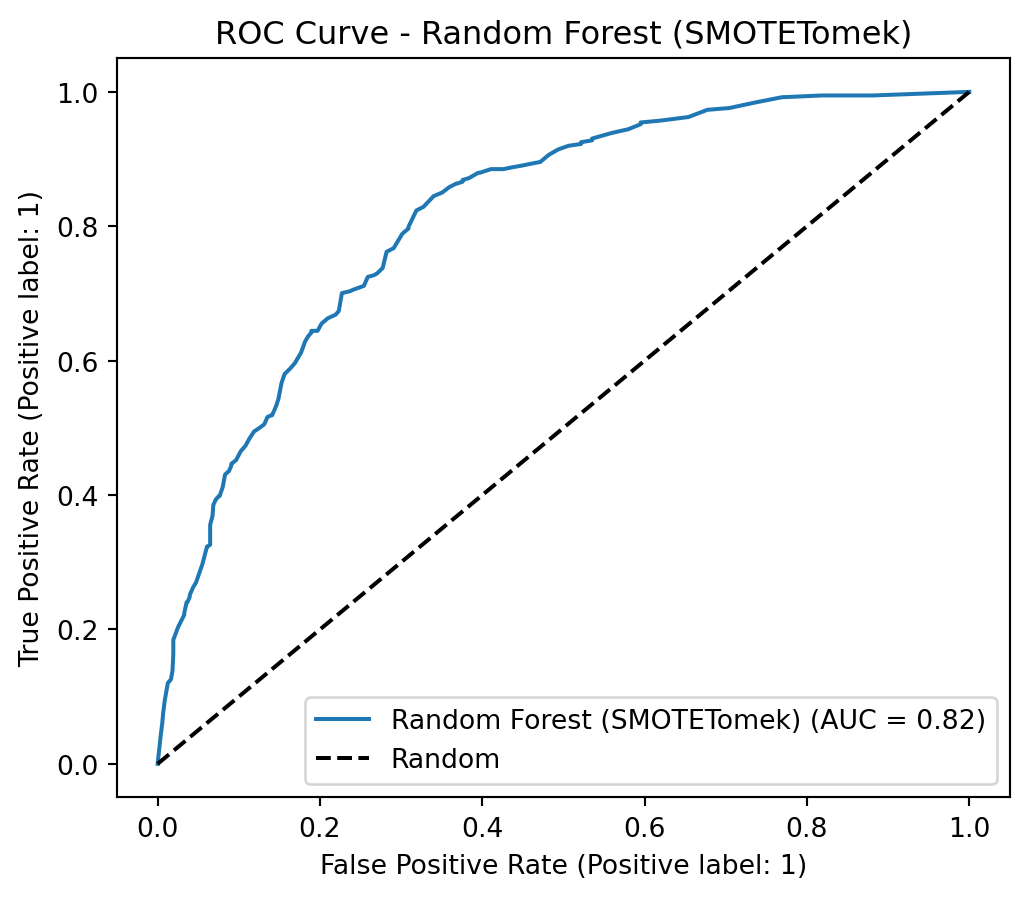
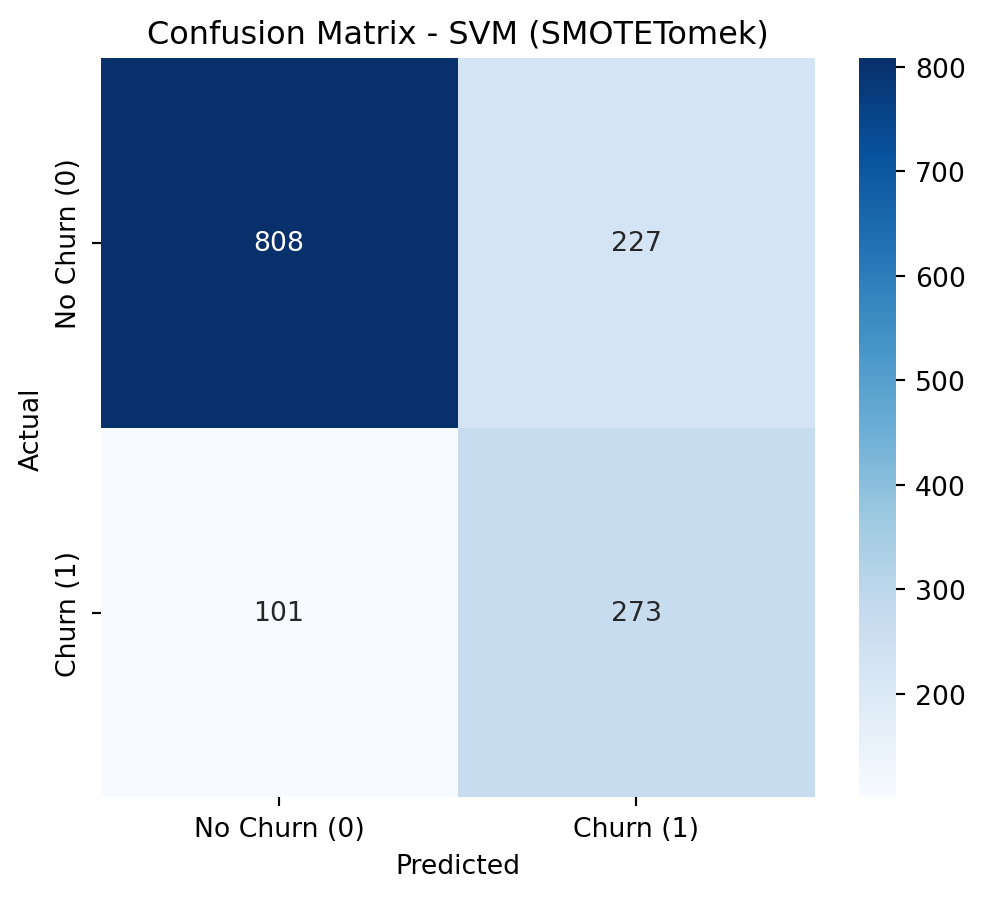
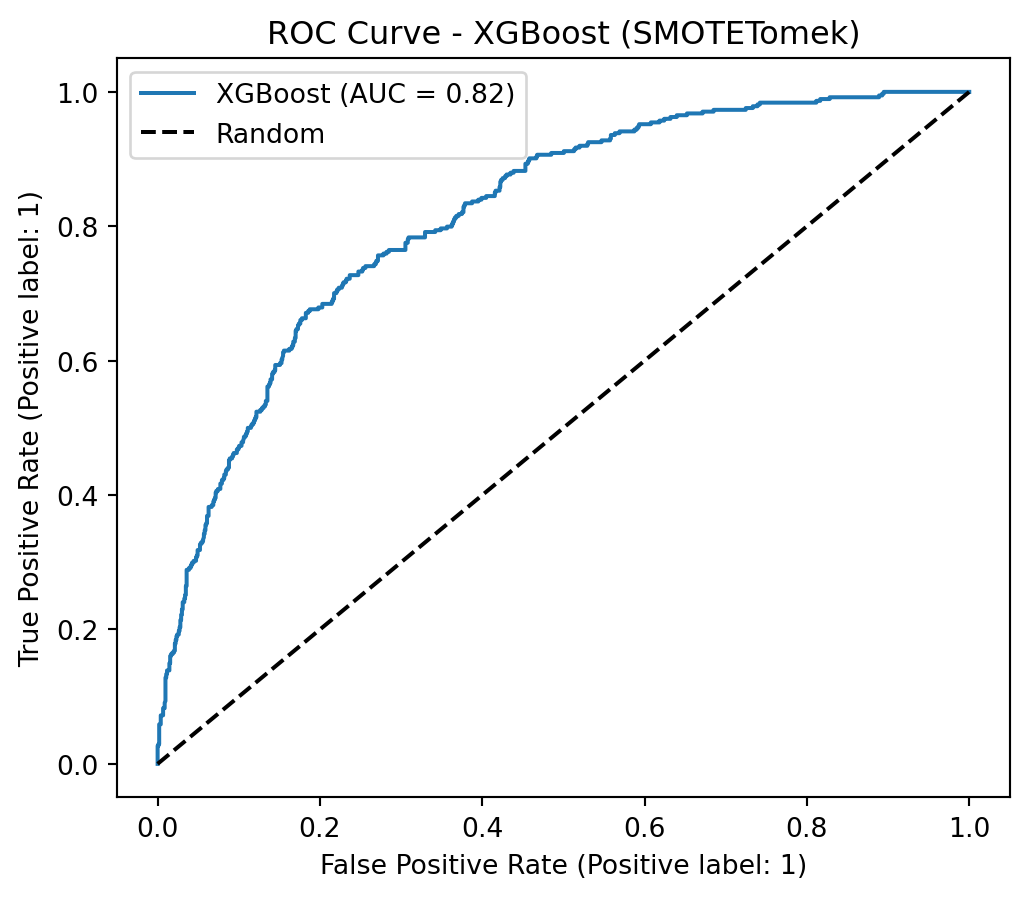
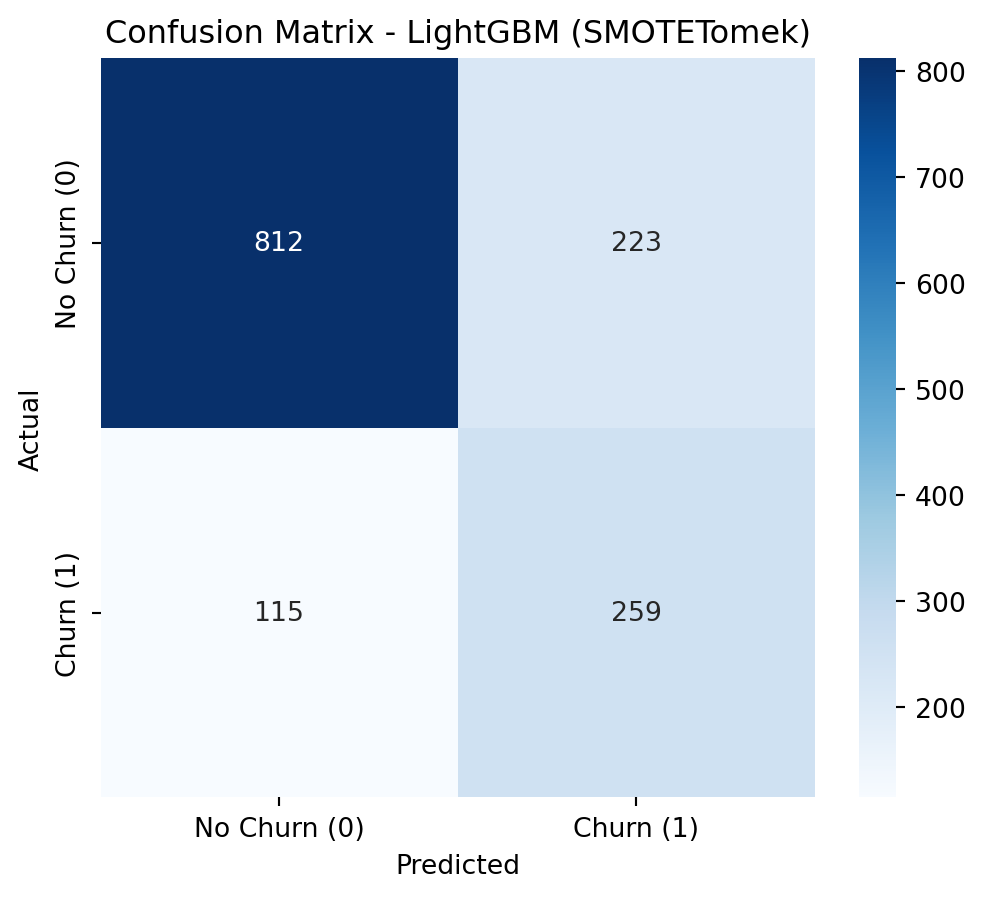
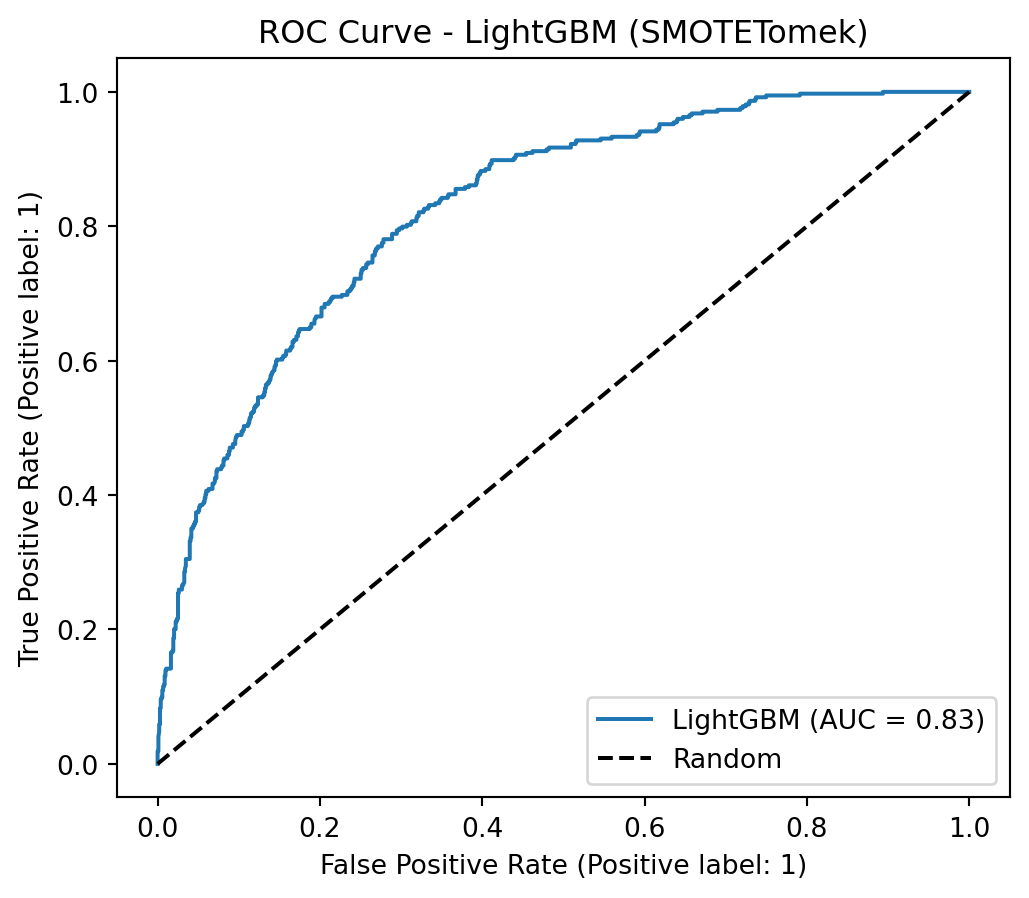
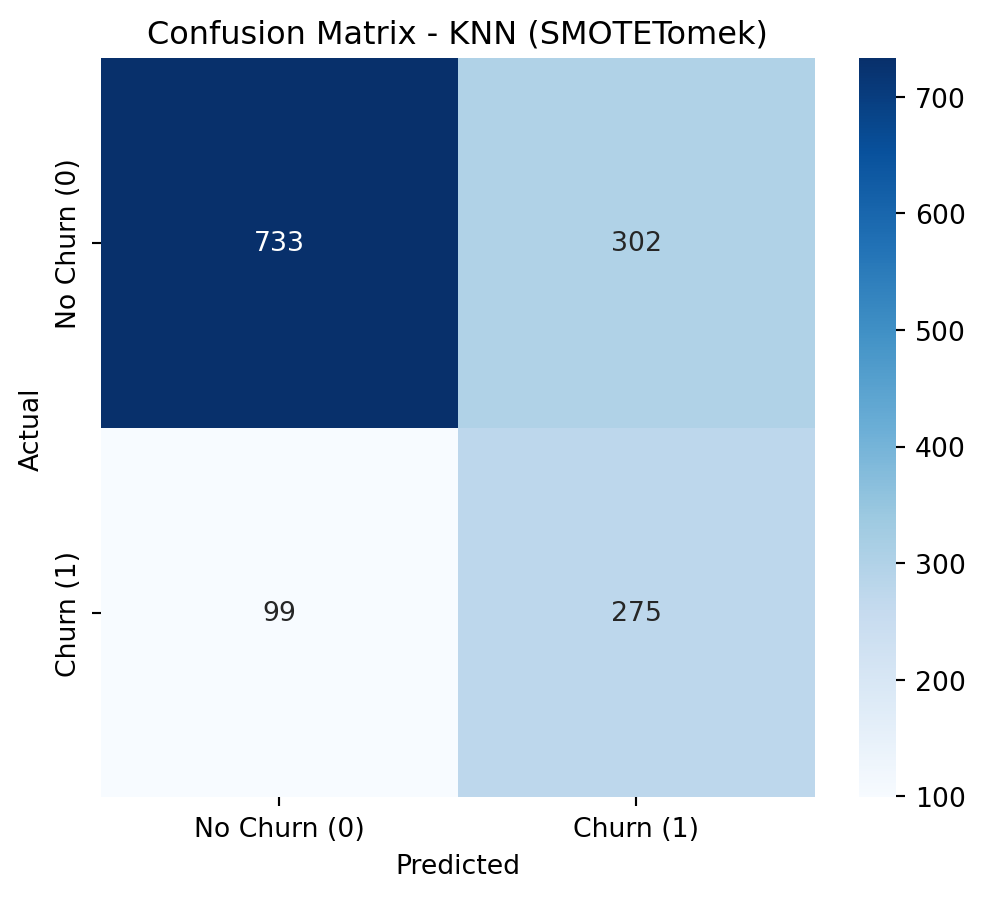
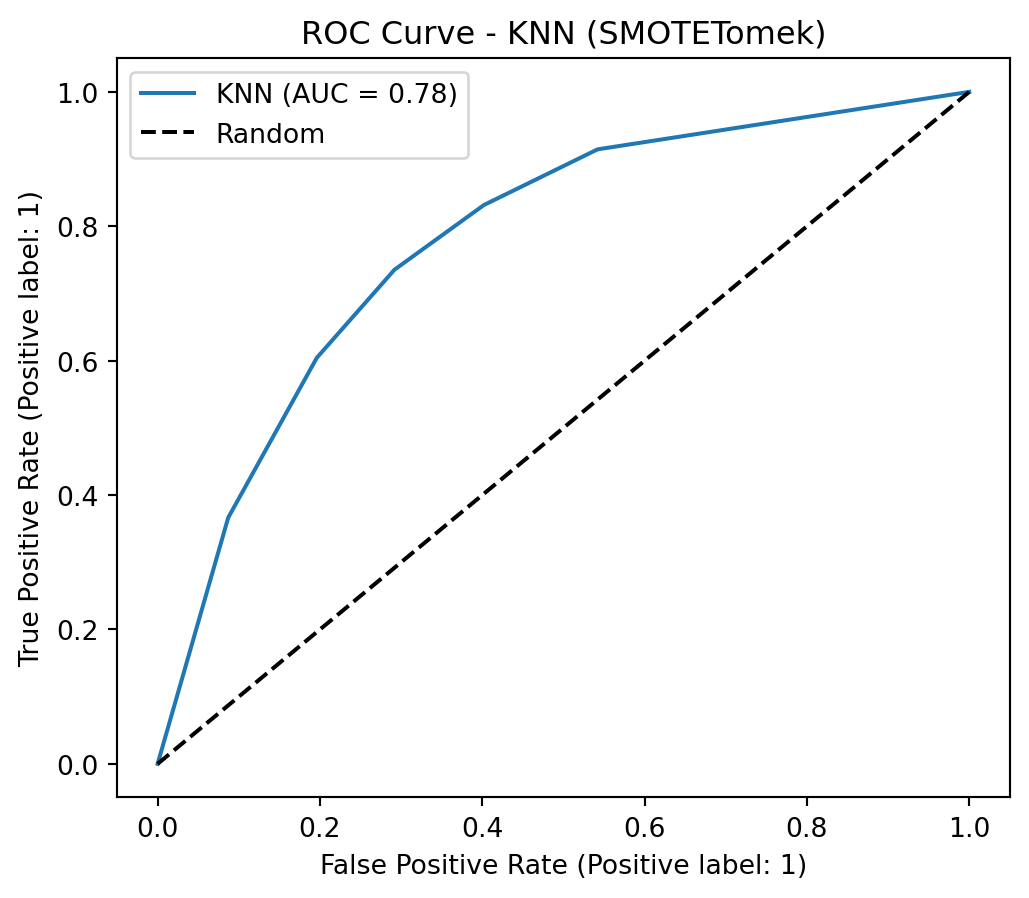
To address class imbalance, a hybrid resampling approach combining SMOTE with undersampling is highly effective. SMOTE (Synthetic Minority Over-sampling Technique) avoids overfitting by creating new, synthetic samples for the minority class based on its nearest neighbors, rather than just duplicating data. This is then coupled with an undersampling technique, such as Tomek Links (as in SMOTETomek), which cleans the feature space by removing majority class samples that are close to the newly created synthetic minority points. This dual strategy results in a more balanced and less noisy dataset, allowing the model to learn a clearer and more robust decision boundary between the classes.
Applying SMOTE + Undersampling (SMOTETomek)
Show Code
smote_tomek = SMOTETomek(random_state=42)X_train_resampled, y_train_resampled = smote_tomek.fit_resample(X_train, y_train)print("\nClass Distribution After Applying SMOTETomek")print(y_train_resampled.value_counts())
Class Distribution After Applying SMOTETomek
Churn
0 3965
1 3965
Name: count, dtype: int64
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
[LightGBM] [Info] Number of positive: 3965, number of negative: 3965
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000879 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 550
[LightGBM] [Info] Number of data points in the train set: 7930, number of used features: 22
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.500000 -> initscore=0.000000
--- Classification Report (LightGBM with SMOTETomek) ---
precision recall f1-score support
0 0.88 0.78 0.83 1035
1 0.54 0.69 0.61 374
accuracy 0.76 1409
macro avg 0.71 0.74 0.72 1409
weighted avg 0.79 0.76 0.77 1409
count_class_0 = y_train.value_counts()[0]count_class_1 = y_train.value_counts()[1]scale_pos_weight_value = count_class_0 / count_class_1print(f"Number of No Churn (class 0) in training set: {count_class_0}")print(f"Number of Churn (class 1) in training set: {count_class_1}")print(f"Calculated scale_pos_weight: {scale_pos_weight_value:.4f}")recall_scorer = make_scorer(recall_score, pos_label=1)
Number of No Churn (class 0) in training set: 4139
Number of Churn (class 1) in training set: 1495
Calculated scale_pos_weight: 2.7686
--- Optimizing Hyperparameters for LightGBM (scale_pos_weight) ---
Fitting 5 folds for each of 243 candidates, totalling 1215 fits
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
[LightGBM] [Info] Number of positive: 1495, number of negative: 4139
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.000778 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 369
[LightGBM] [Info] Number of data points in the train set: 5634, number of used features: 22
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.265353 -> initscore=-1.018328
[LightGBM] [Info] Start training from score -1.018328
Best Parameters (LightGBM): {'learning_rate': 0.05, 'n_estimators': 100, 'num_leaves': 20, 'reg_alpha': 0.5, 'reg_lambda': 0.5}
Best Recall (LightGBM) on CV: 0.7873
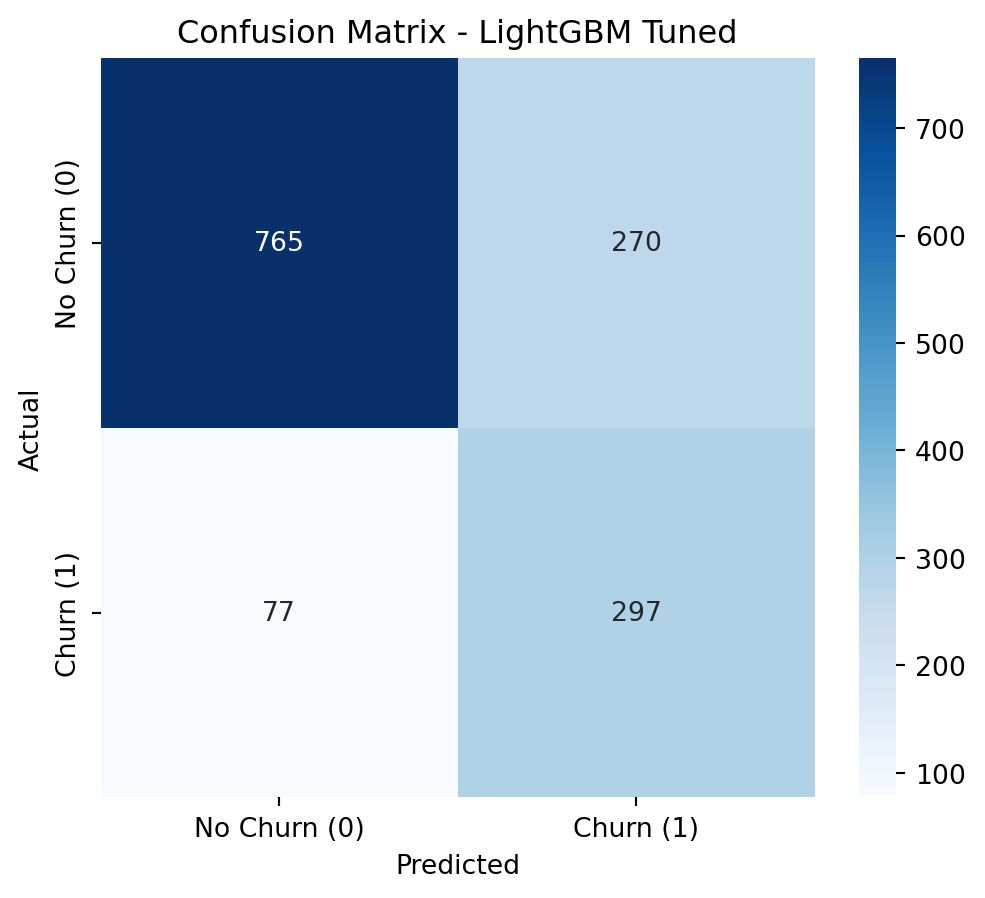
--- Classification Report (LightGBM Tuned) ---
precision recall f1-score support
0 0.91 0.74 0.82 1035
1 0.52 0.79 0.63 374
accuracy 0.75 1409
macro avg 0.72 0.77 0.72 1409
weighted avg 0.81 0.75 0.77 1409
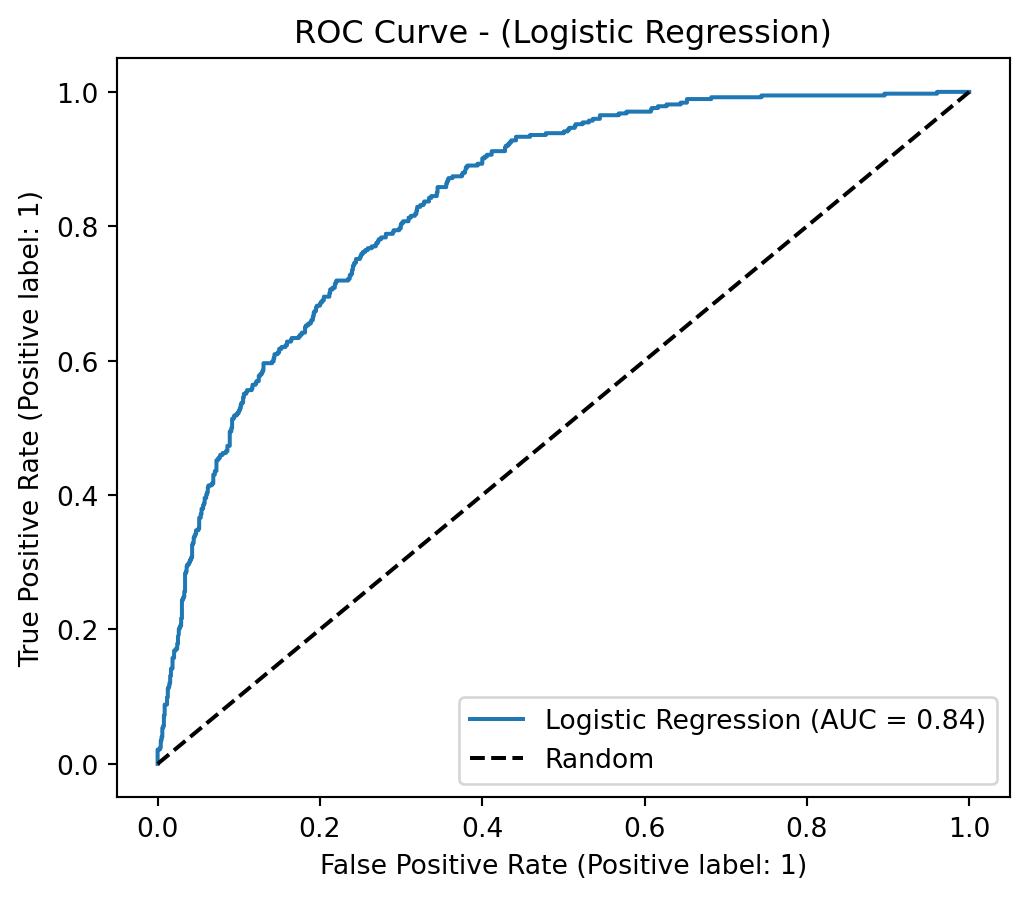
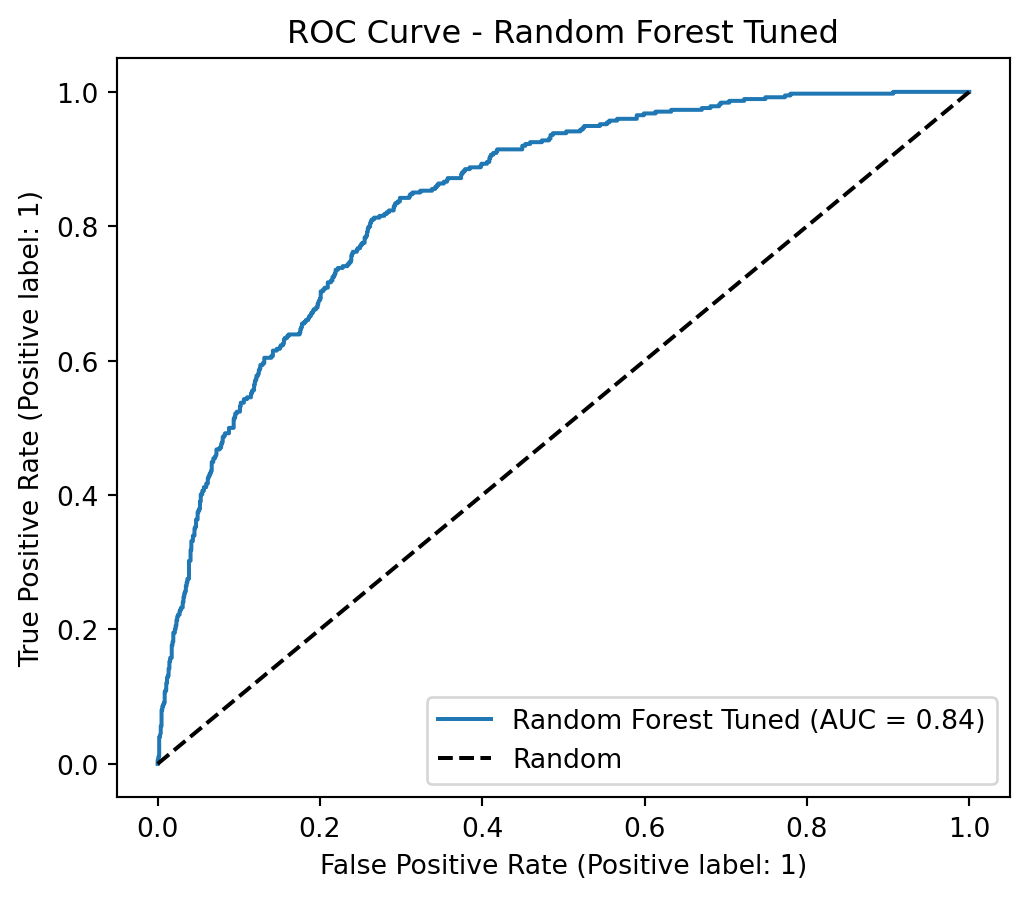
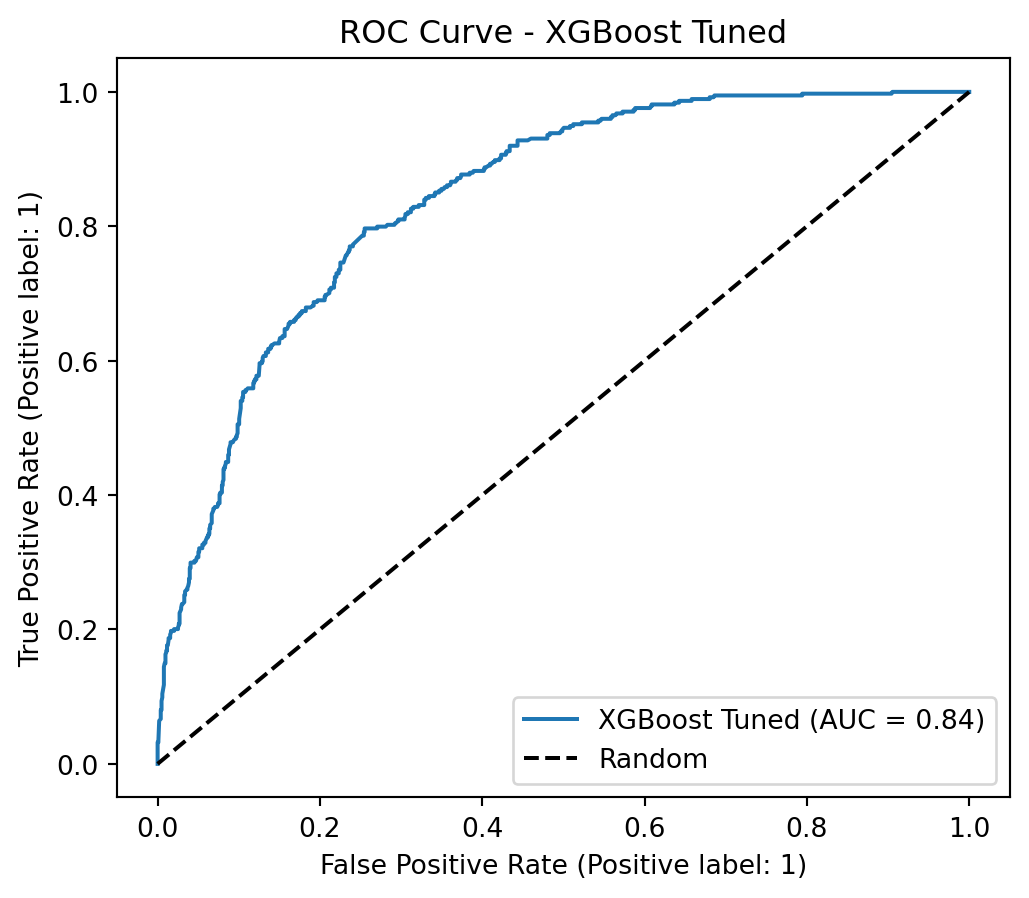
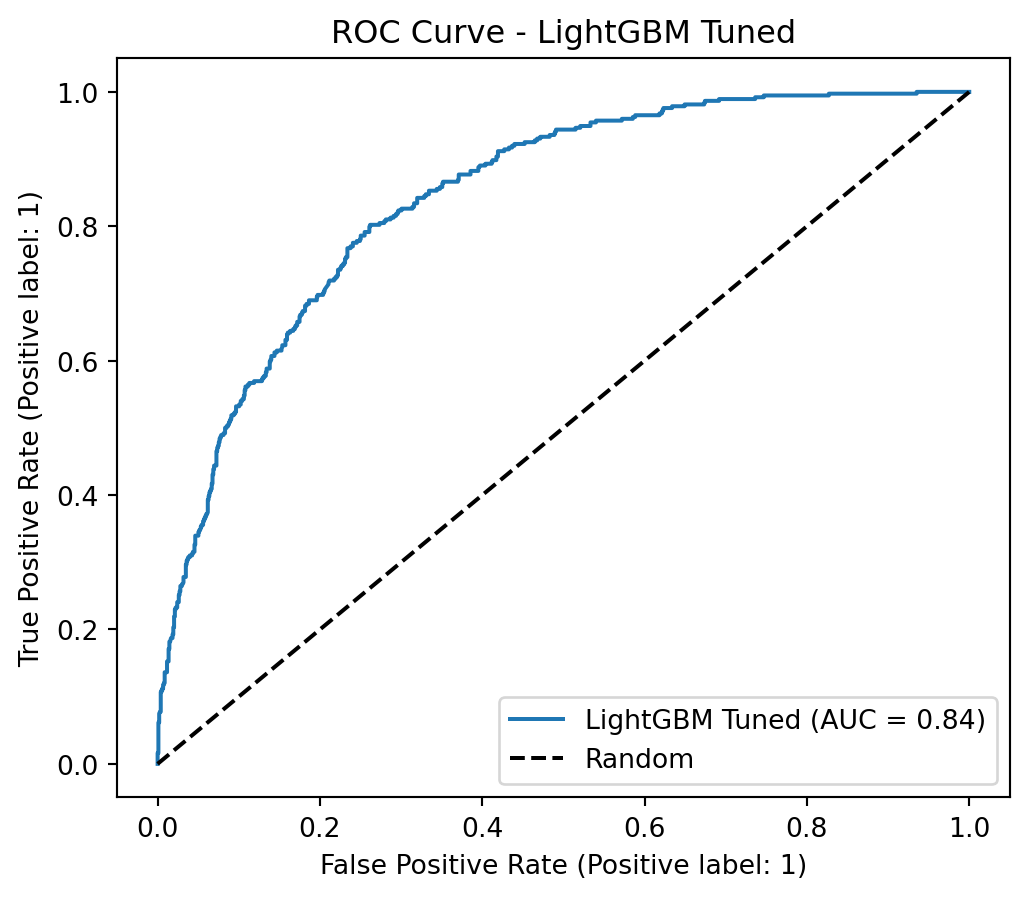
AUC-ROC (LightGBM Tuned): 0.8428
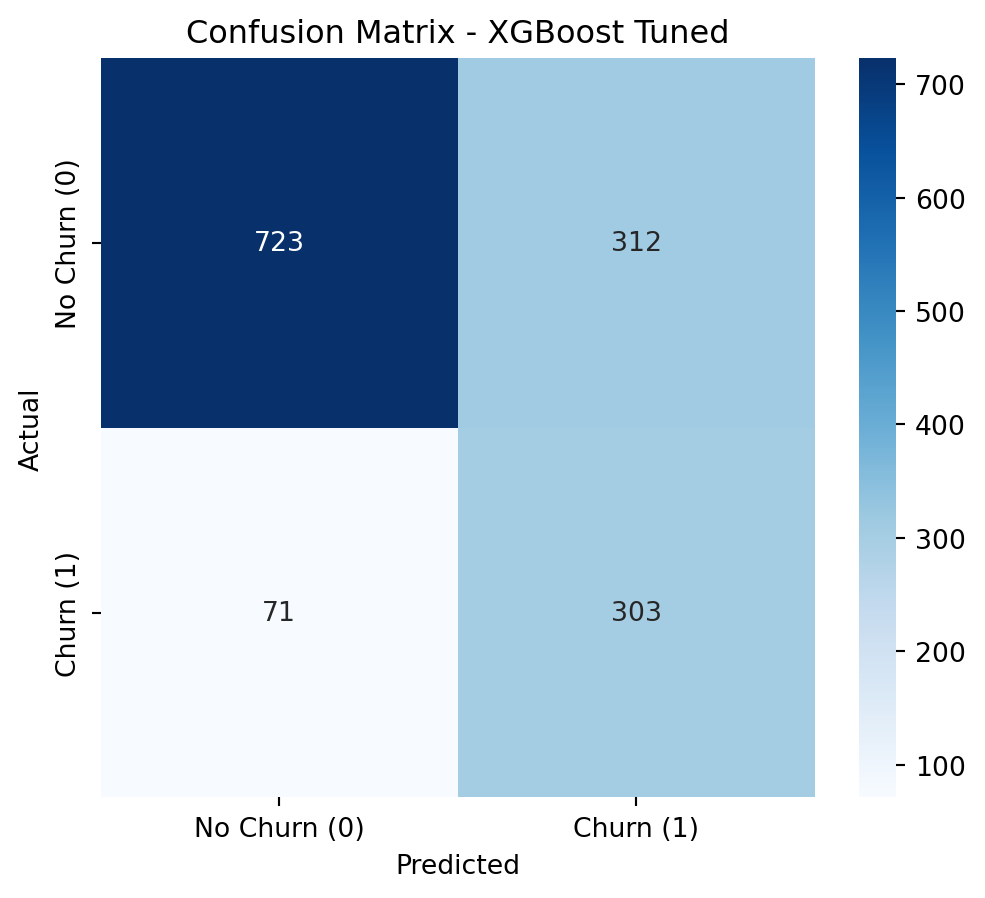
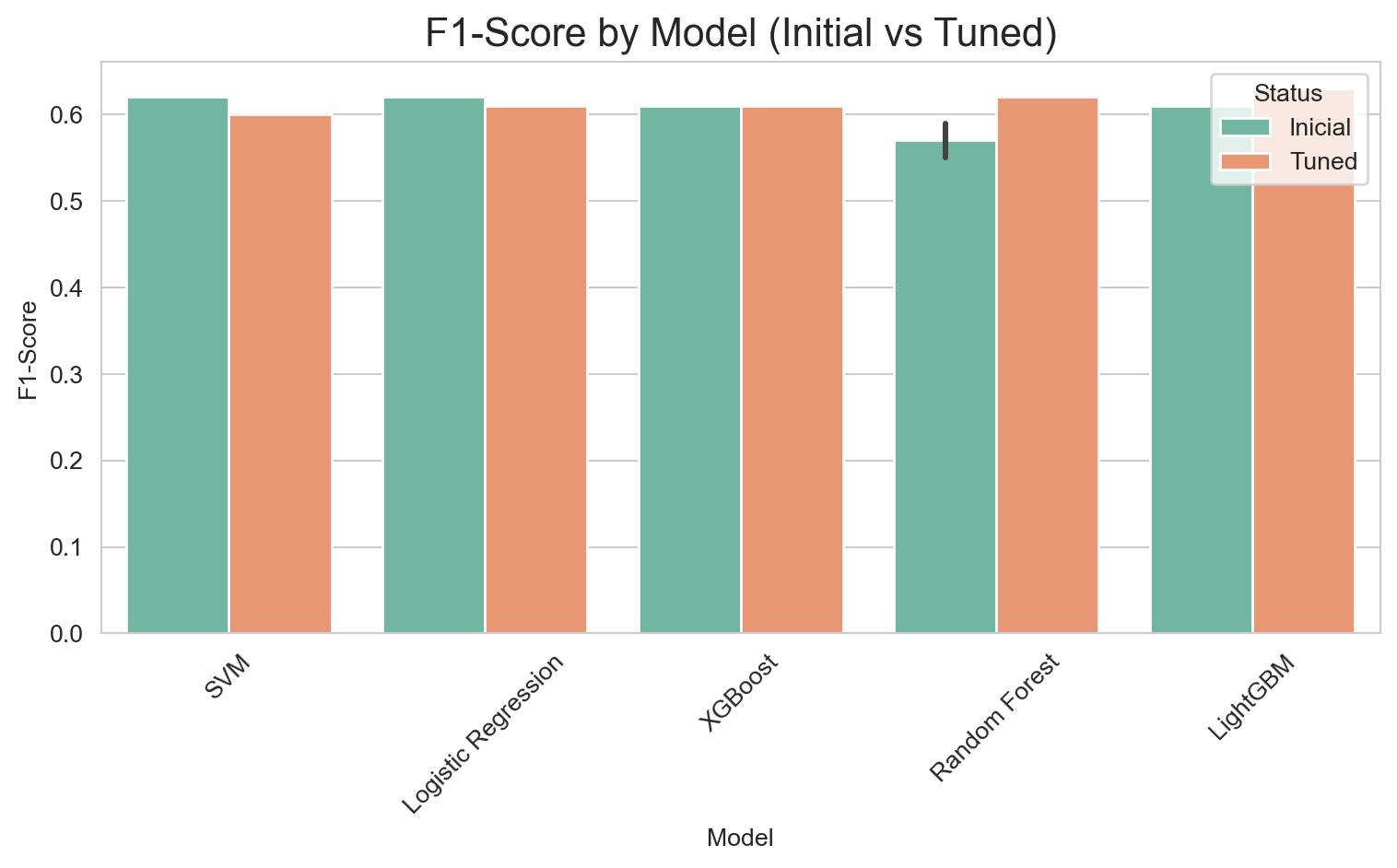
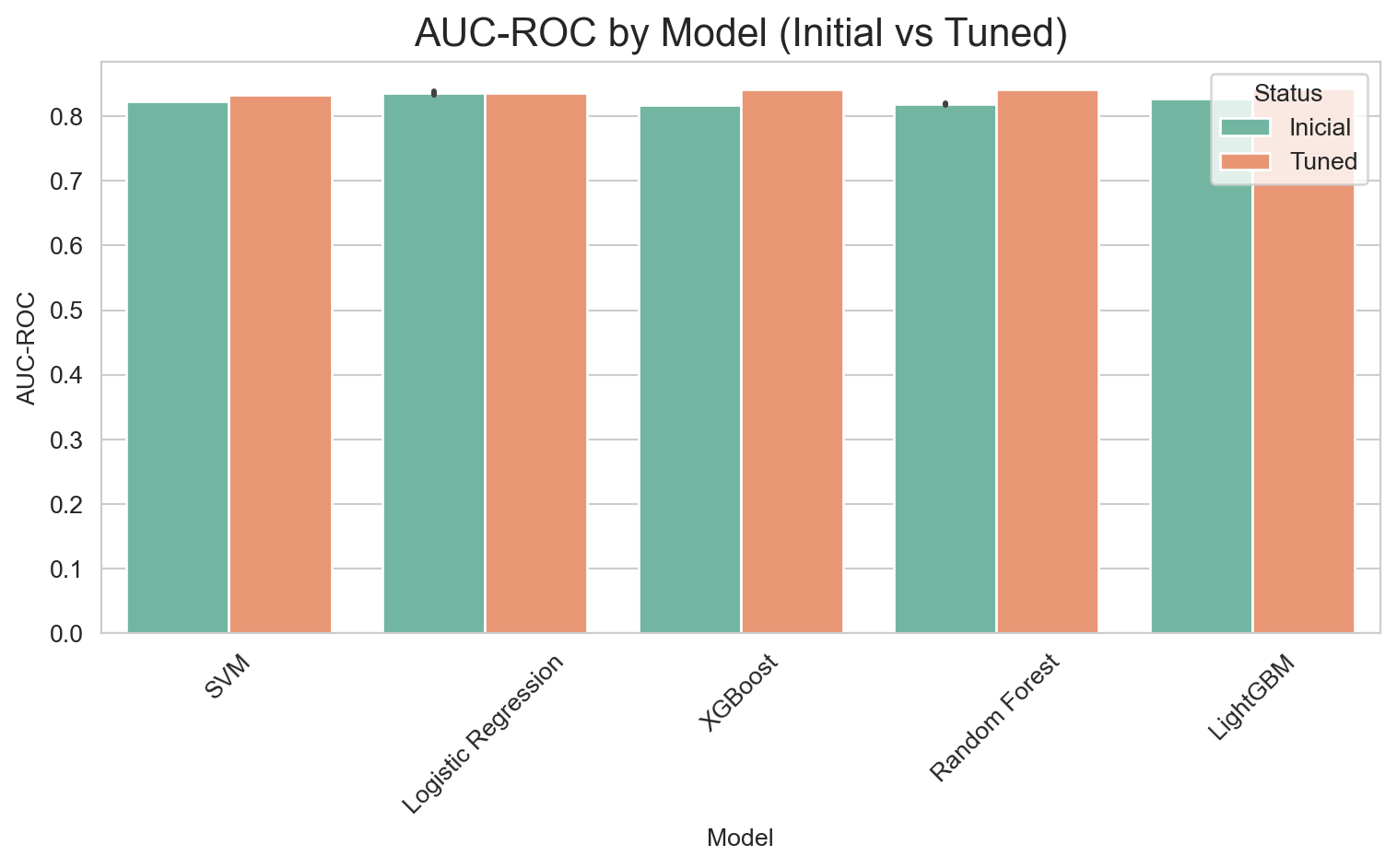
The optimized versions with scale_pos_weight consistently outperform their SMOTETomek-based counterparts in AUC, Recall, and F1-Score. The conclusion is that, for this problem and dataset, using class_weight and scale_pos_weight in conjunction with hyperparameter optimization was the most effective strategy for achieving high Recall and AUC, surpassing the resampling approach with SMOTETomek.
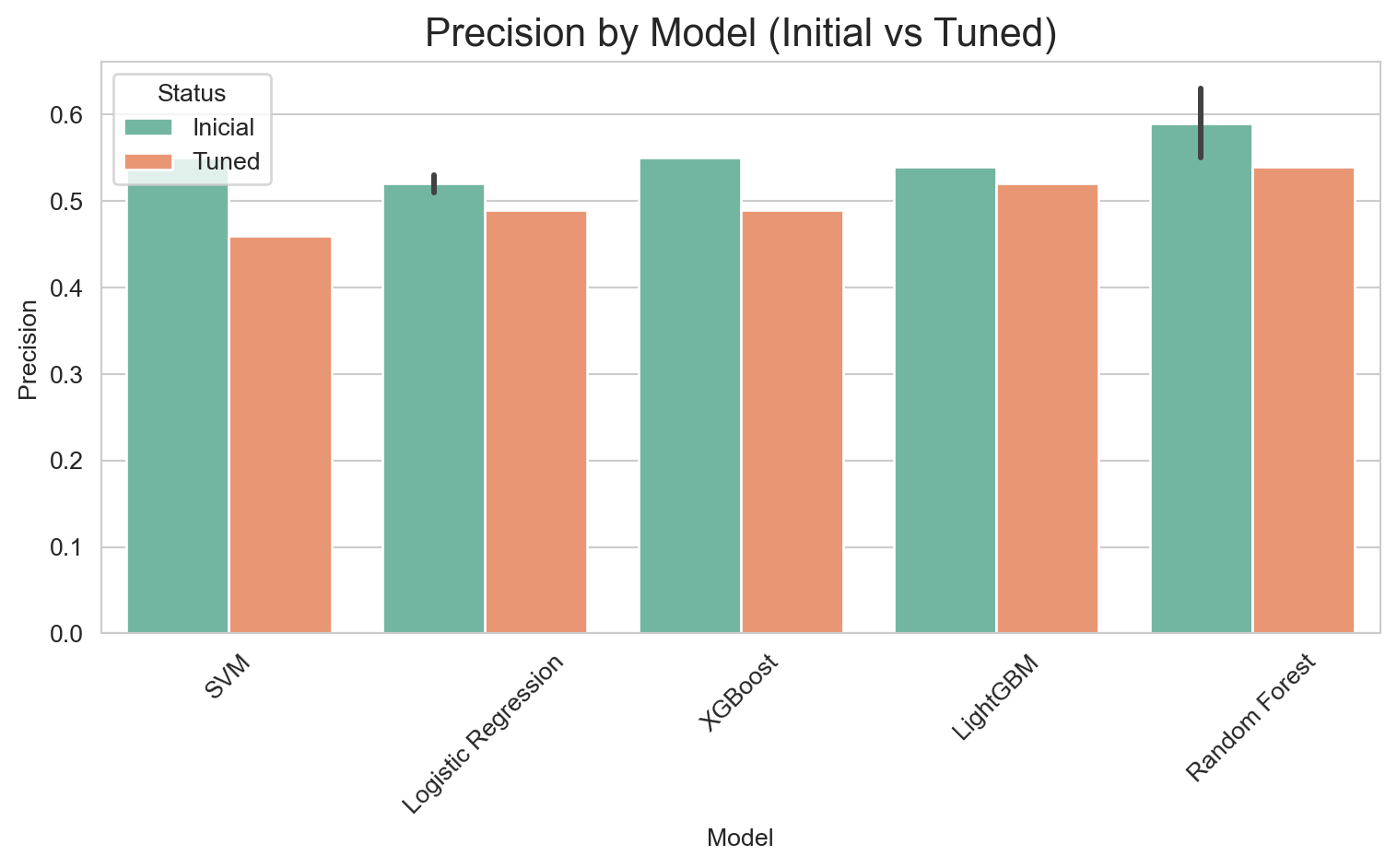
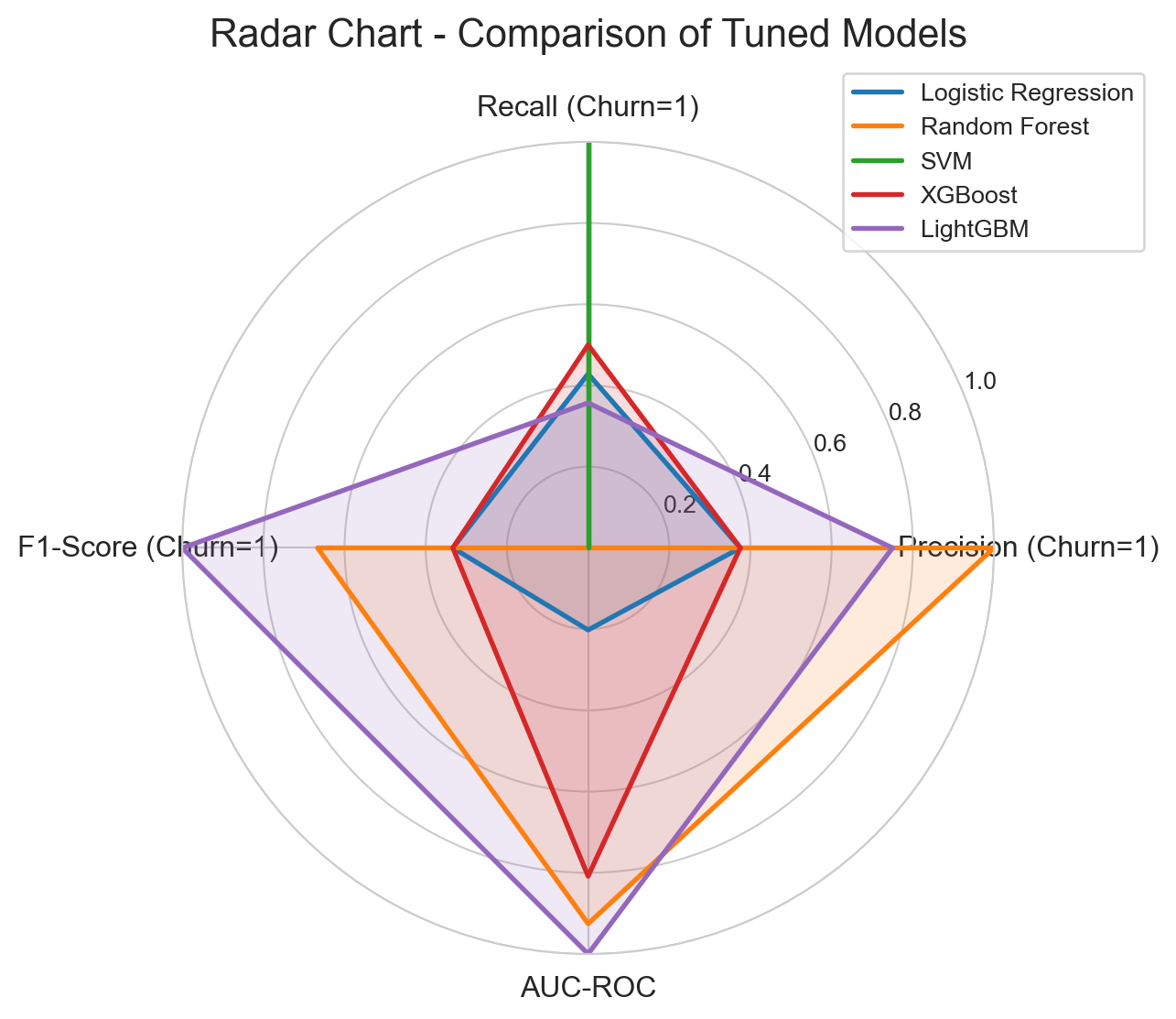
Considering the results, the most promising models are:
Optimized LightGBM: Highest AUC and F1-Score, and an excellent Recall (0.79). It offers the best overall balance.
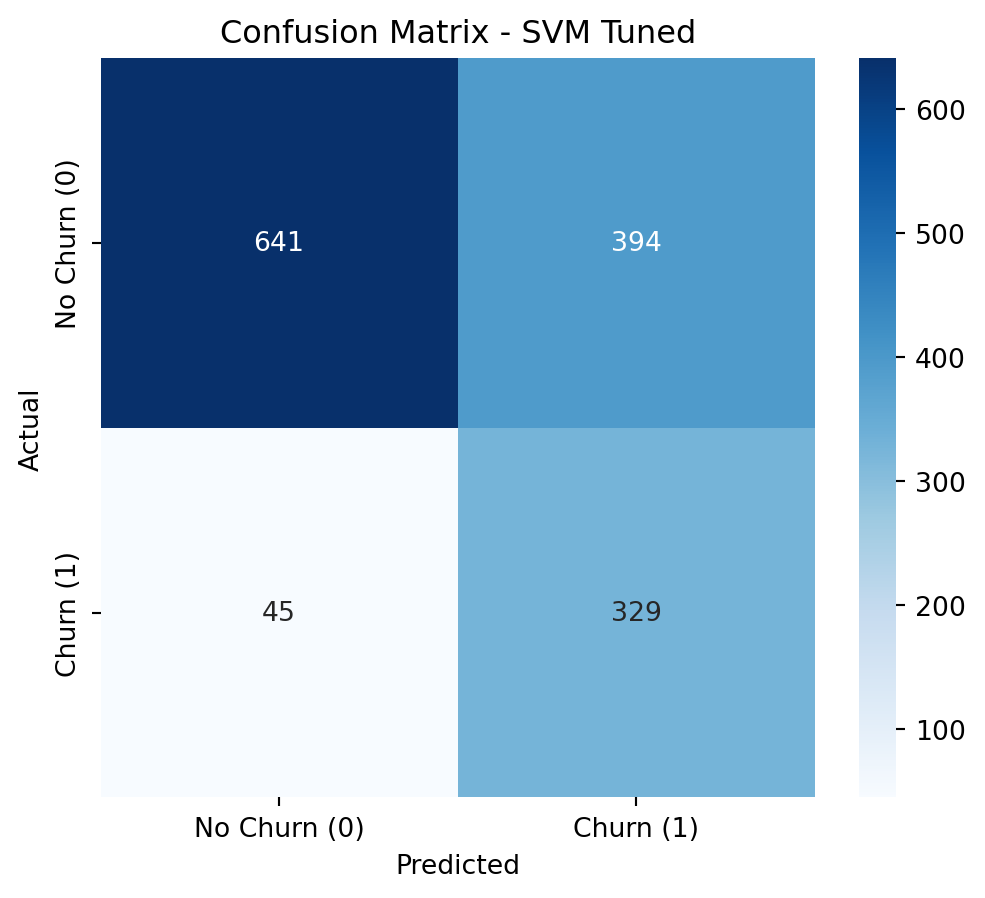
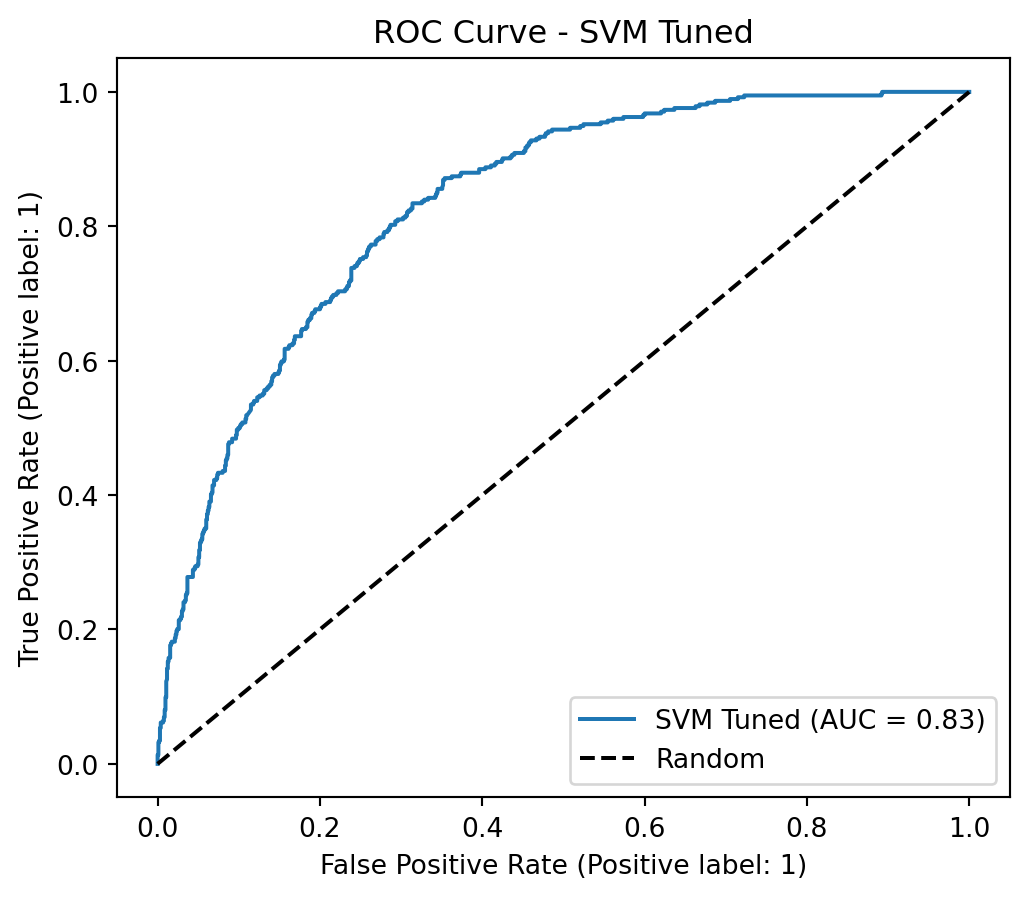
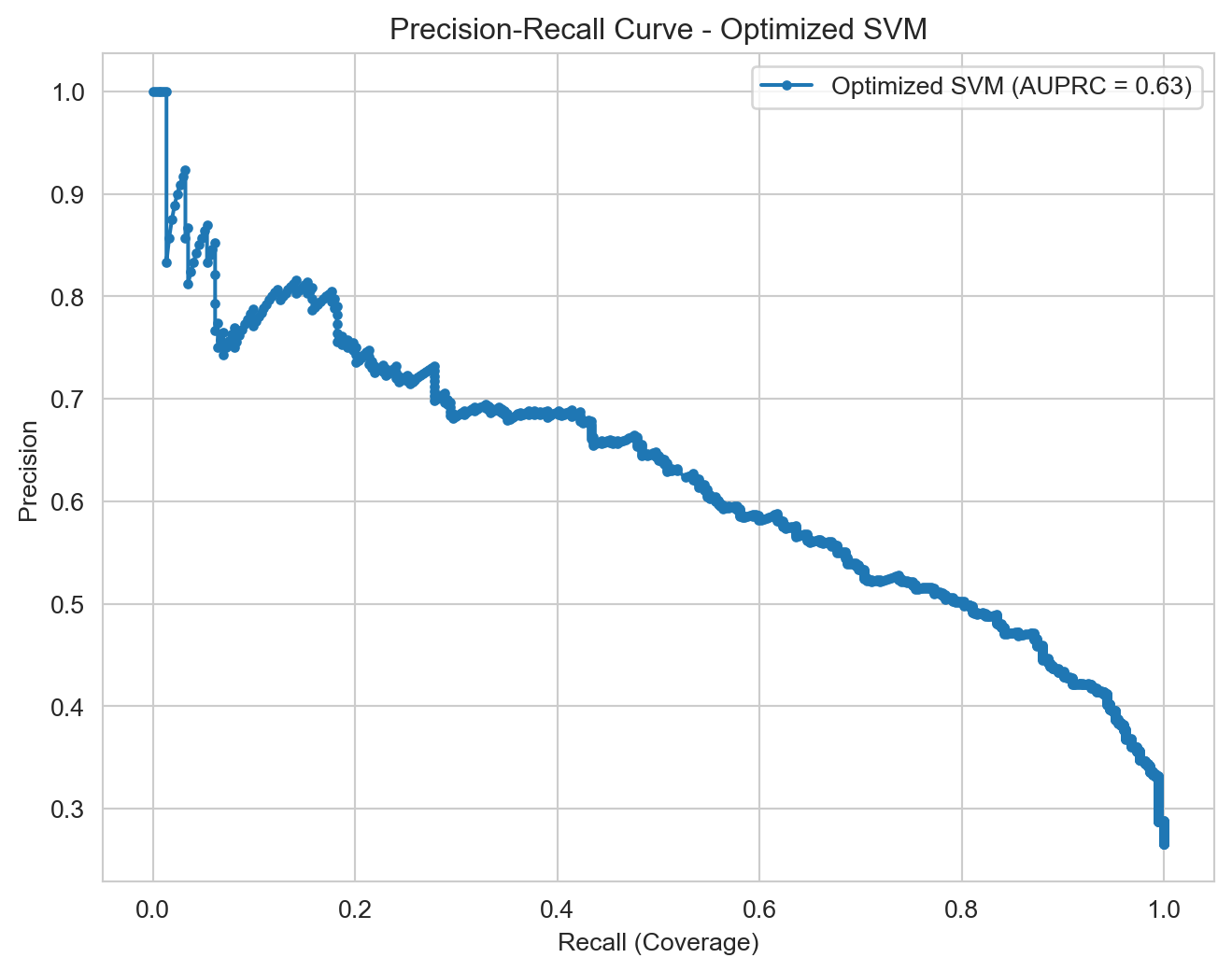
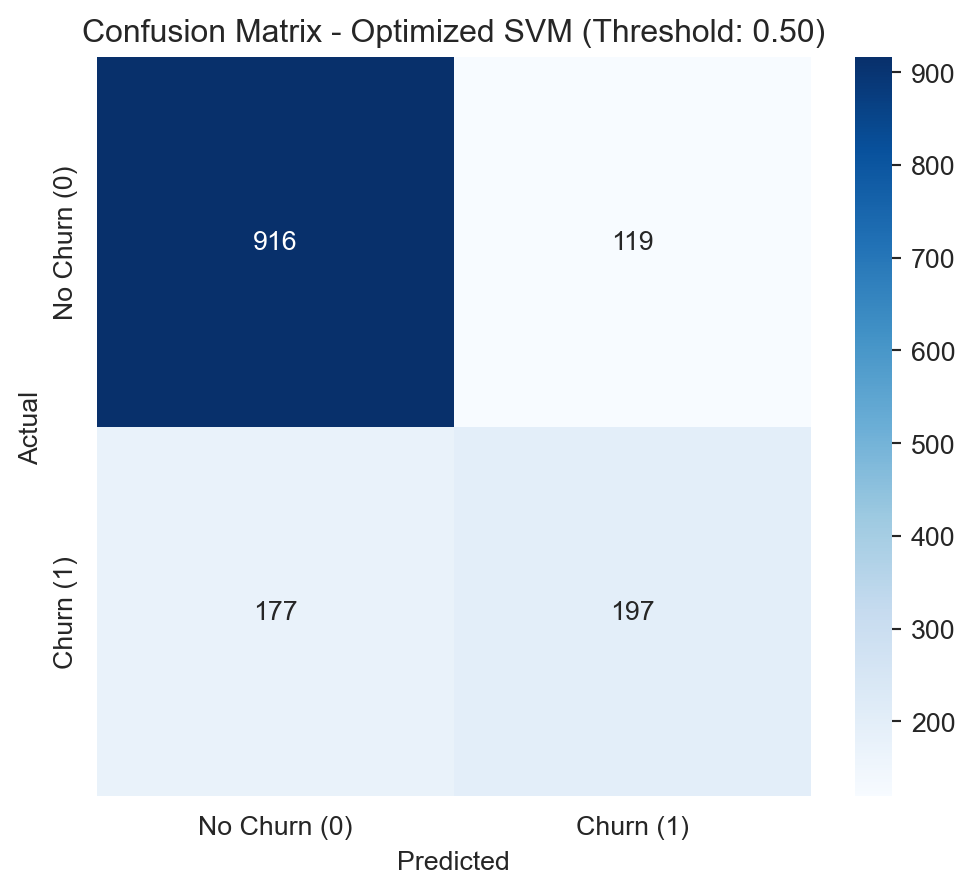
Optimized SVM: Highest Recall (0.88), but with the lowest Precision (0.46). It is important to evaluate if the cost of False Positives is justified by the extremely high Recall.
Treshold Tunning
Now that we have optimized models with excellent metrics, the next step is threshold tuning.
All the models we have used have a default classification threshold of 0.5. This means that if the predicted probability of churn is >= 0.5, the customer is classified as “churn”; otherwise, they are classified as “no churn”. However, for our problem, where Recall is the priority and Precision is a secondary concern, the 0.5 threshold may not be optimal.
We need to find a cutoff point that maximizes Recall for the “Churn” class (to avoid missing customers who are going to cancel), while maintaining Precision at an acceptable level (to avoid spending excessive resources on False Positives).
Considering our primary objective to prioritize Recall (capturing the maximum number of churners), without completely disregarding Precision (to avoid wasting resources):
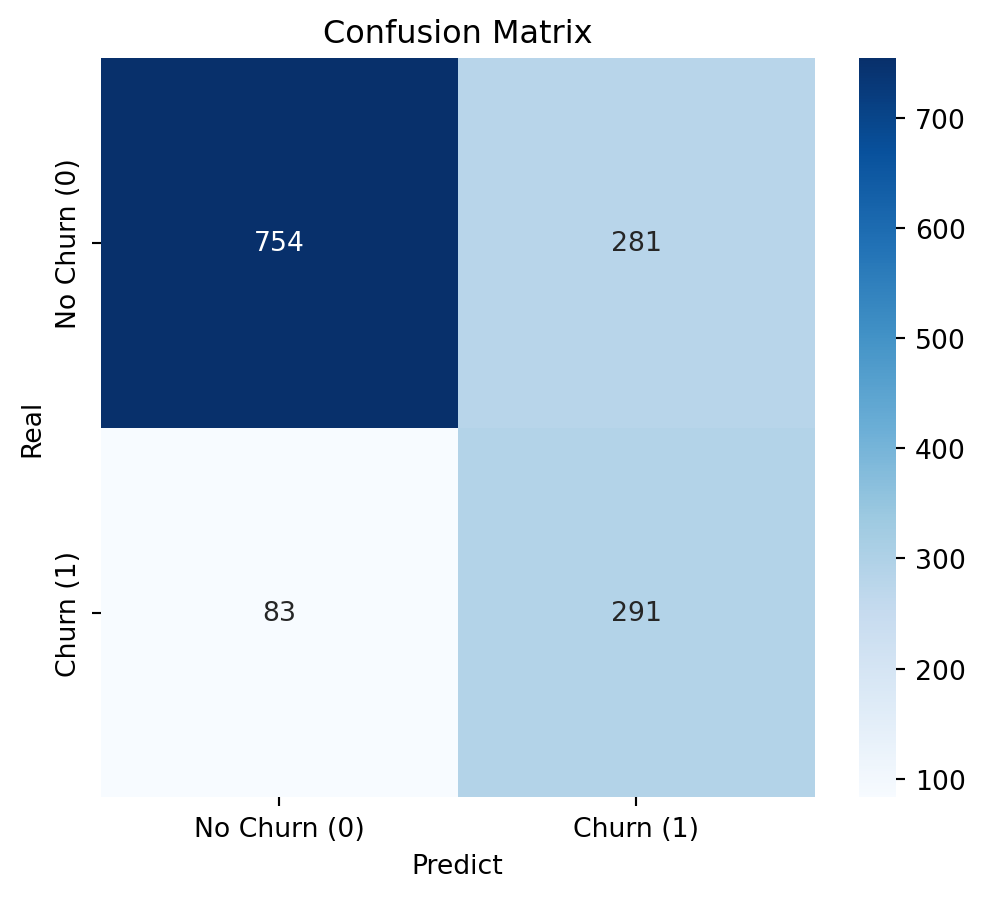
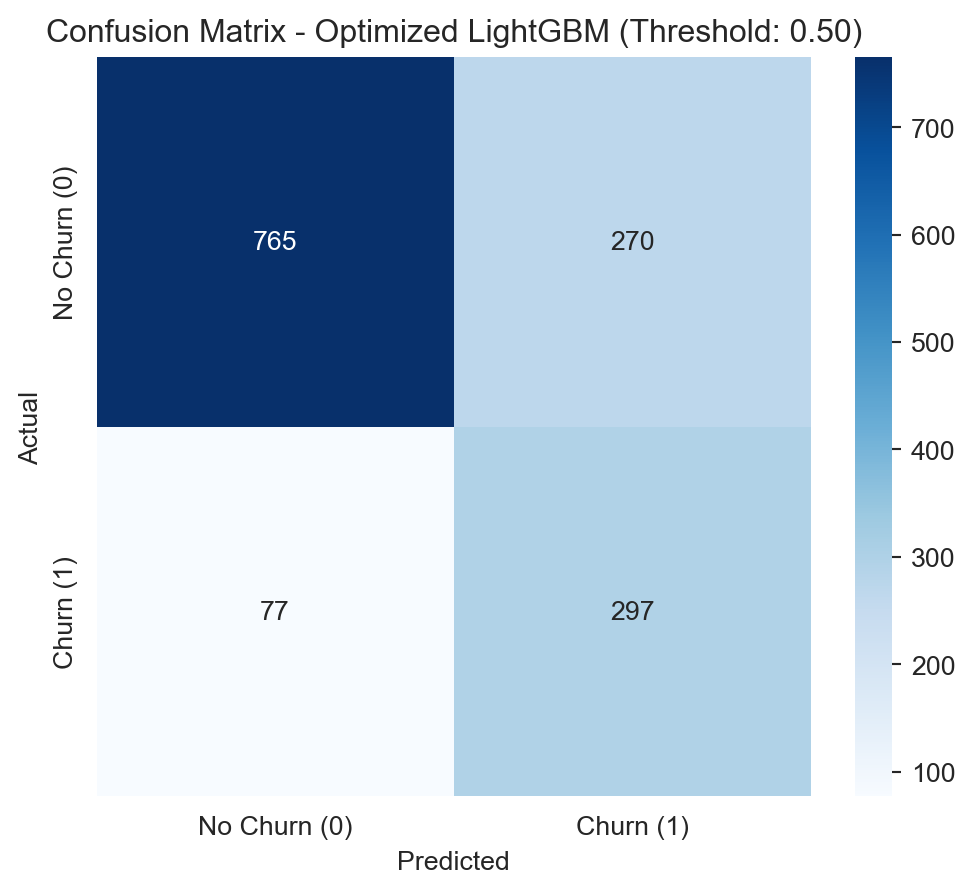
The Optimized LightGBM with the default cutoff point of 0.50 proves to be the most balanced and effective choice.
It achieves a Recall of 0.79, meaning it correctly identifies 79% of the customers who will actually cancel. This is excellent for proactive retention.
It maintains a Precision of 0.52, which indicates that of the customers the model flags as potential churners, a little over half will actually cancel. This implies a manageable cost of False Positives.
Its F1-Score of 0.63 is the highest among the optimized models, confirming its strong balance.
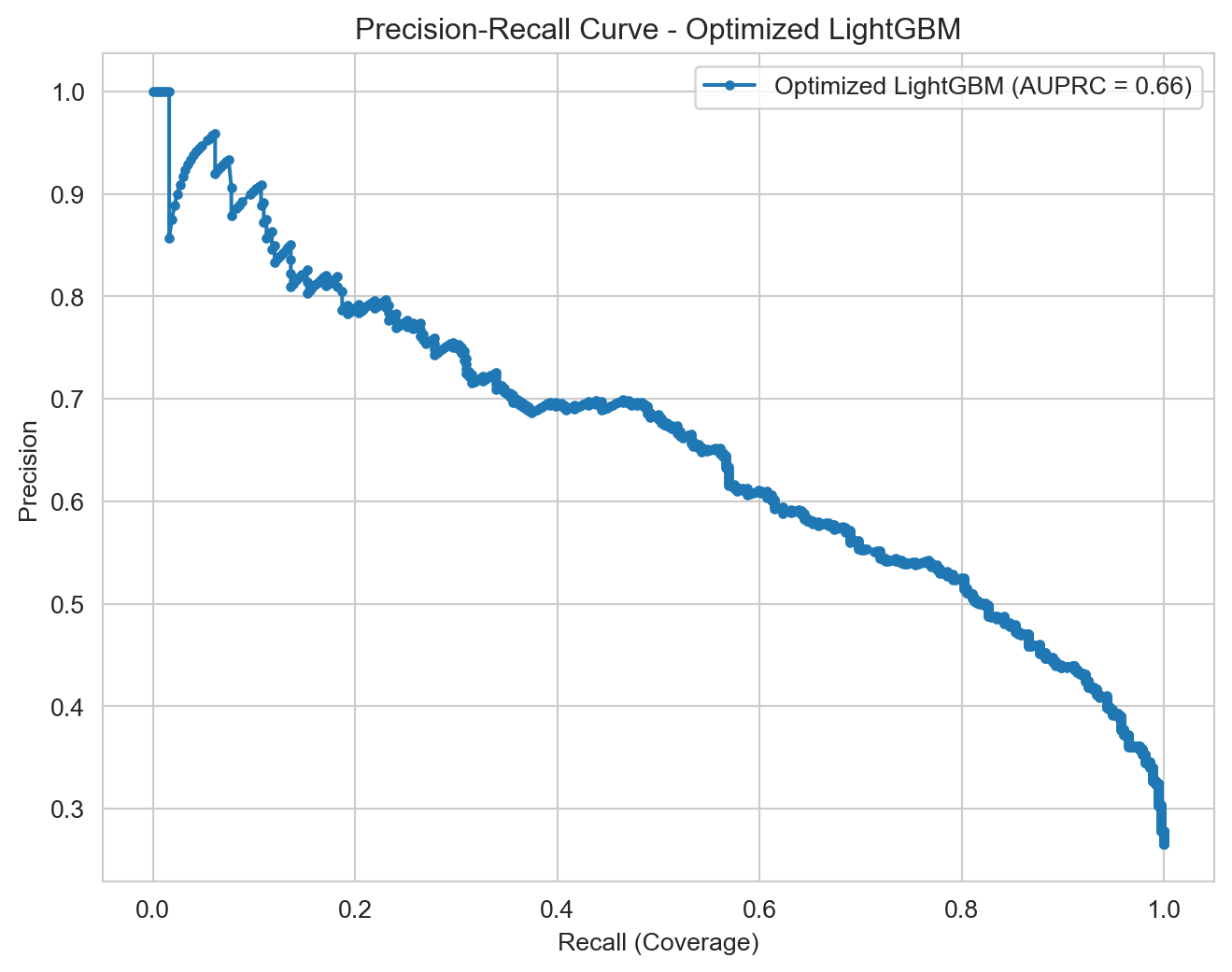
Its AUPRC (0.6565) and AUC-ROC (0.8428) are the highest, attesting to its overall robustness.
The Optimized SVM is impressive for its potential for an extremely high Recall (reaching 0.88 at lower thresholds), but the drop in Precision would be too steep (below 0.50) to justify its selection for this project. This would only be viable if the cost of a False Positive were absolutely negligible, which is rarely the case in retention strategies.
The Optimized LightGBM, using its default cutoff point of 0.50, offers the best balance between detecting customers who will actually cancel (79% Recall) and minimizing unnecessary interventions (52% Precision). This balance is ideal for a business strategy where the priority is to retain customers, ensuring that the majority of potential churners are identified, while simultaneously optimizing the use of retention resources. Its superior performance in AUPRC and AUC-ROC also attests to its overall discriminatory power.
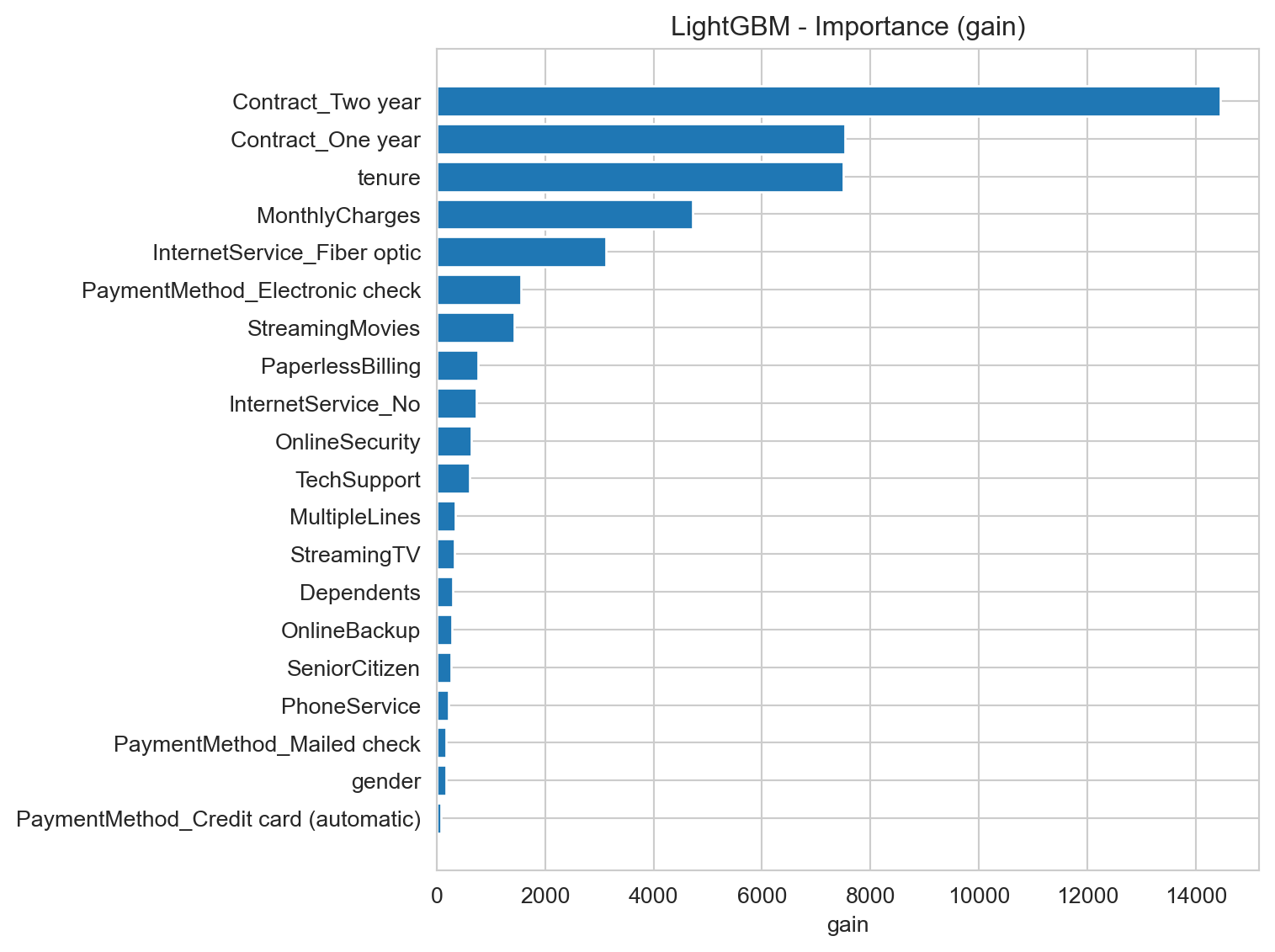
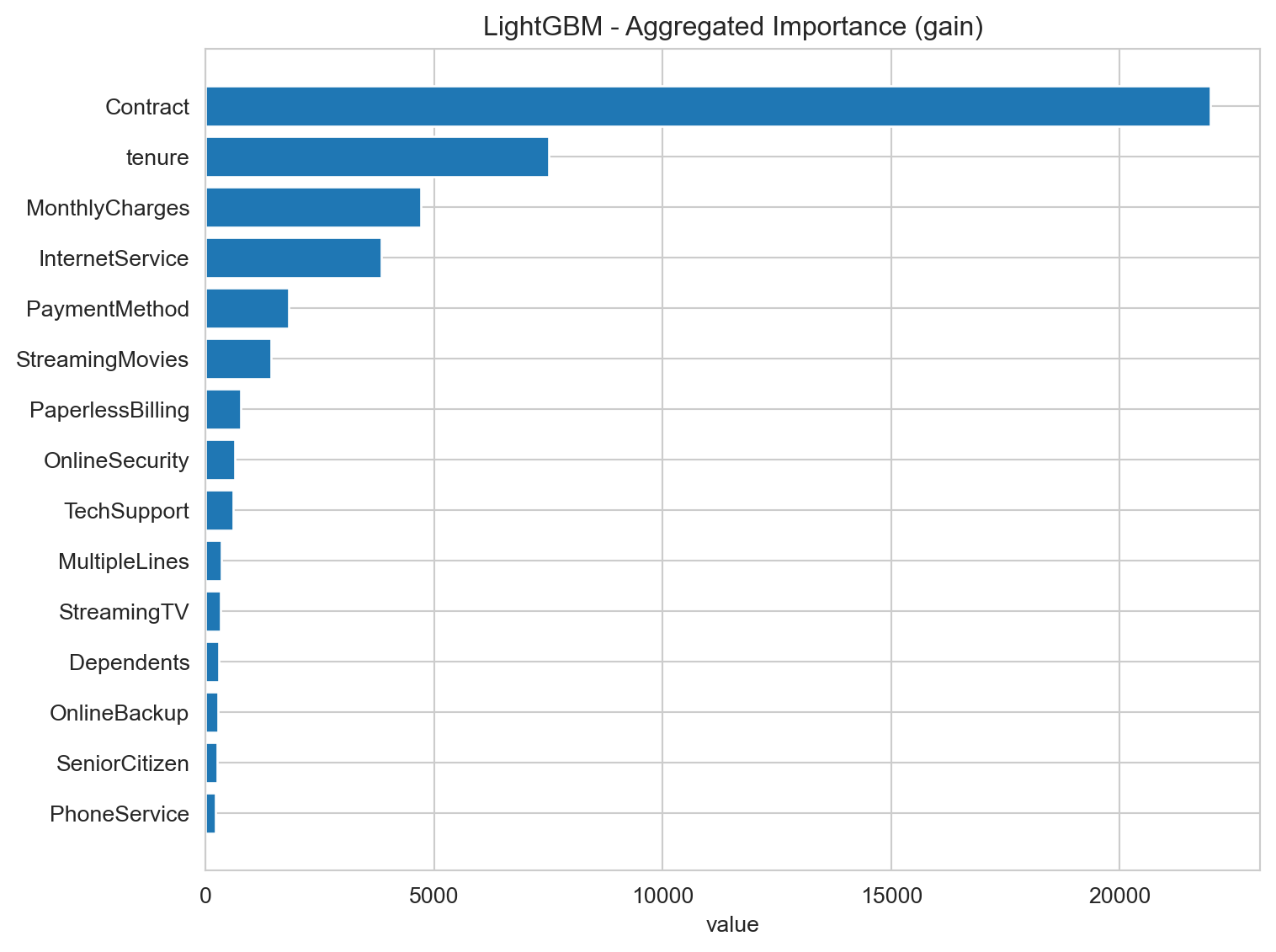
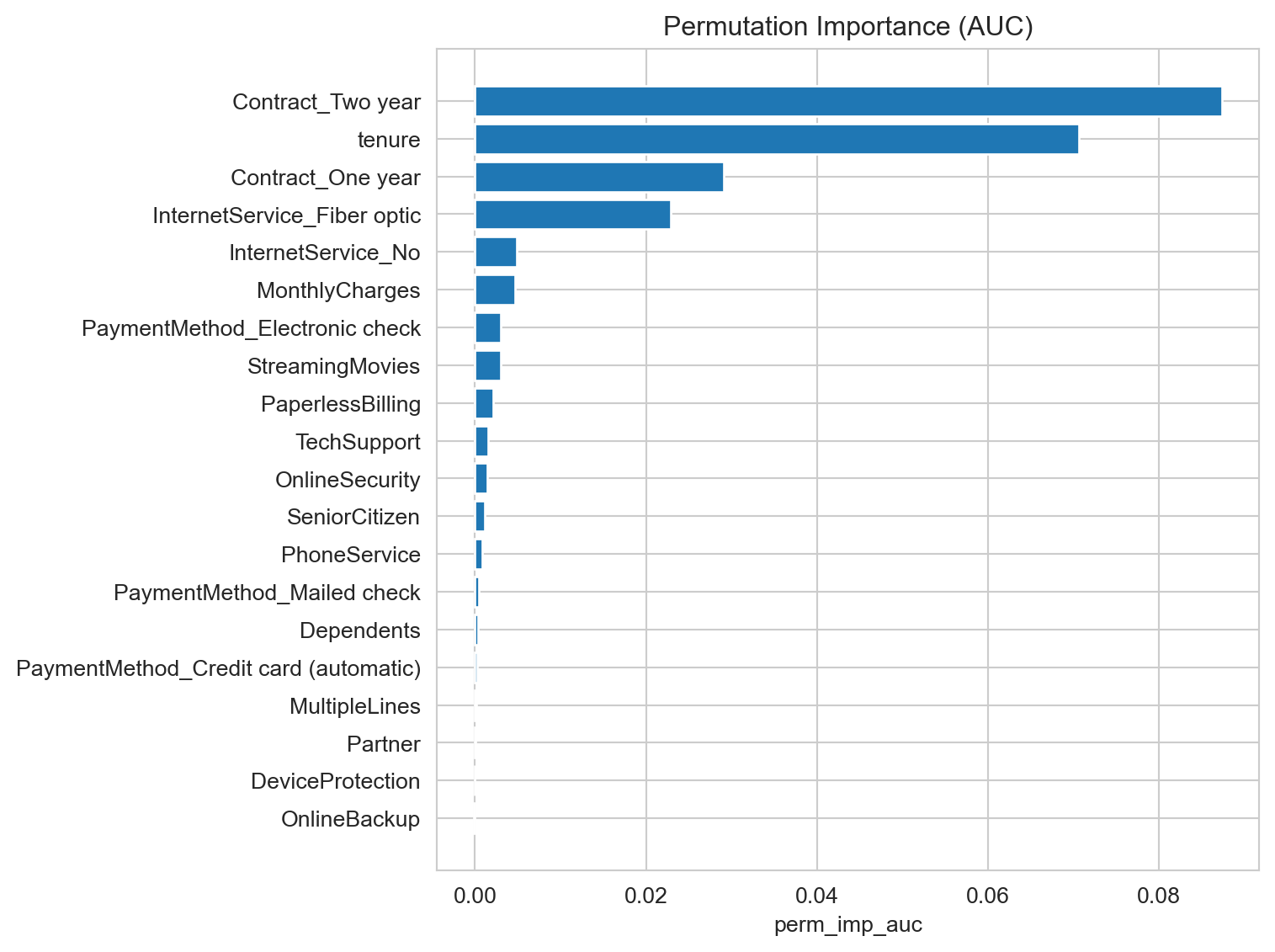
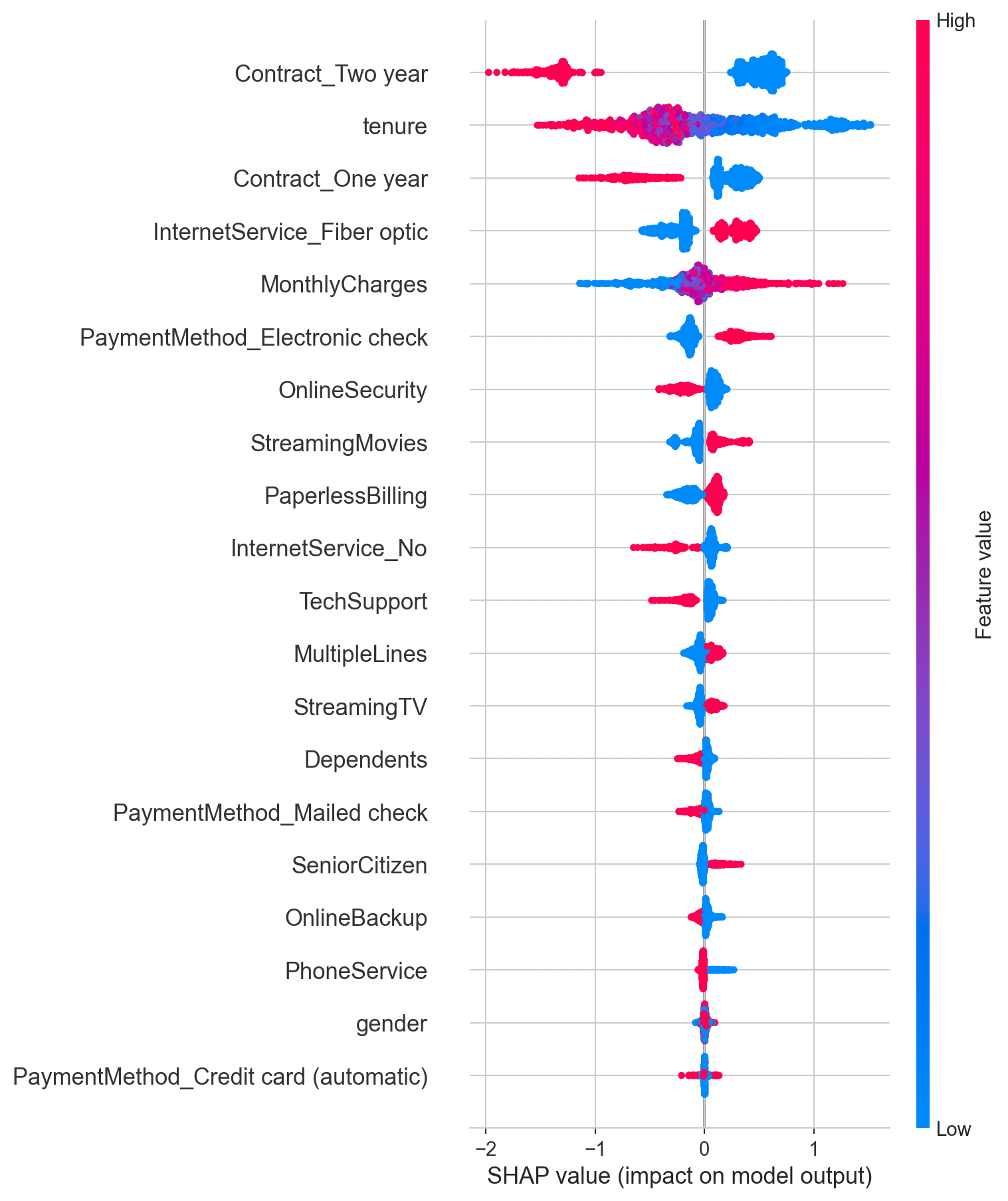
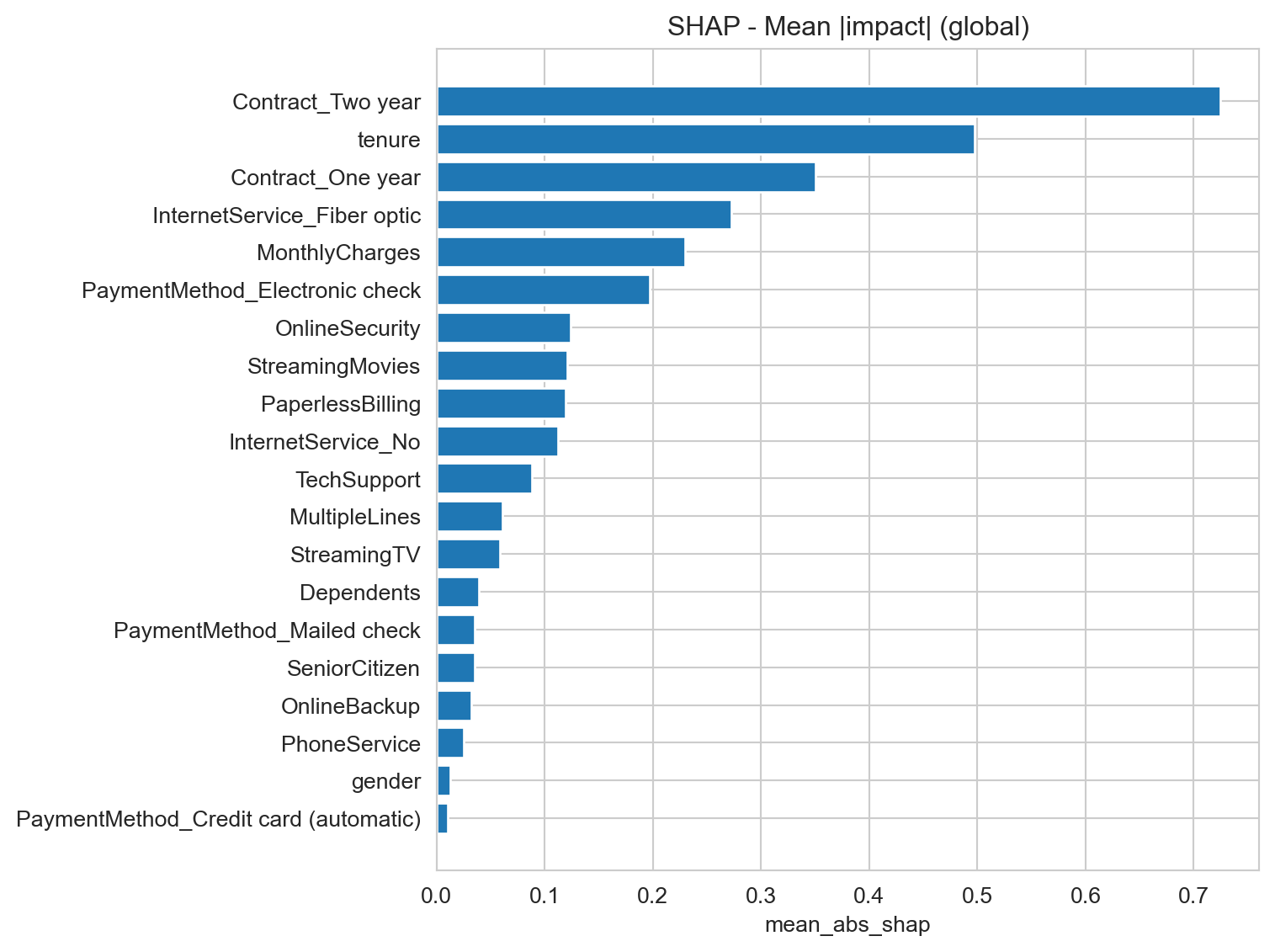
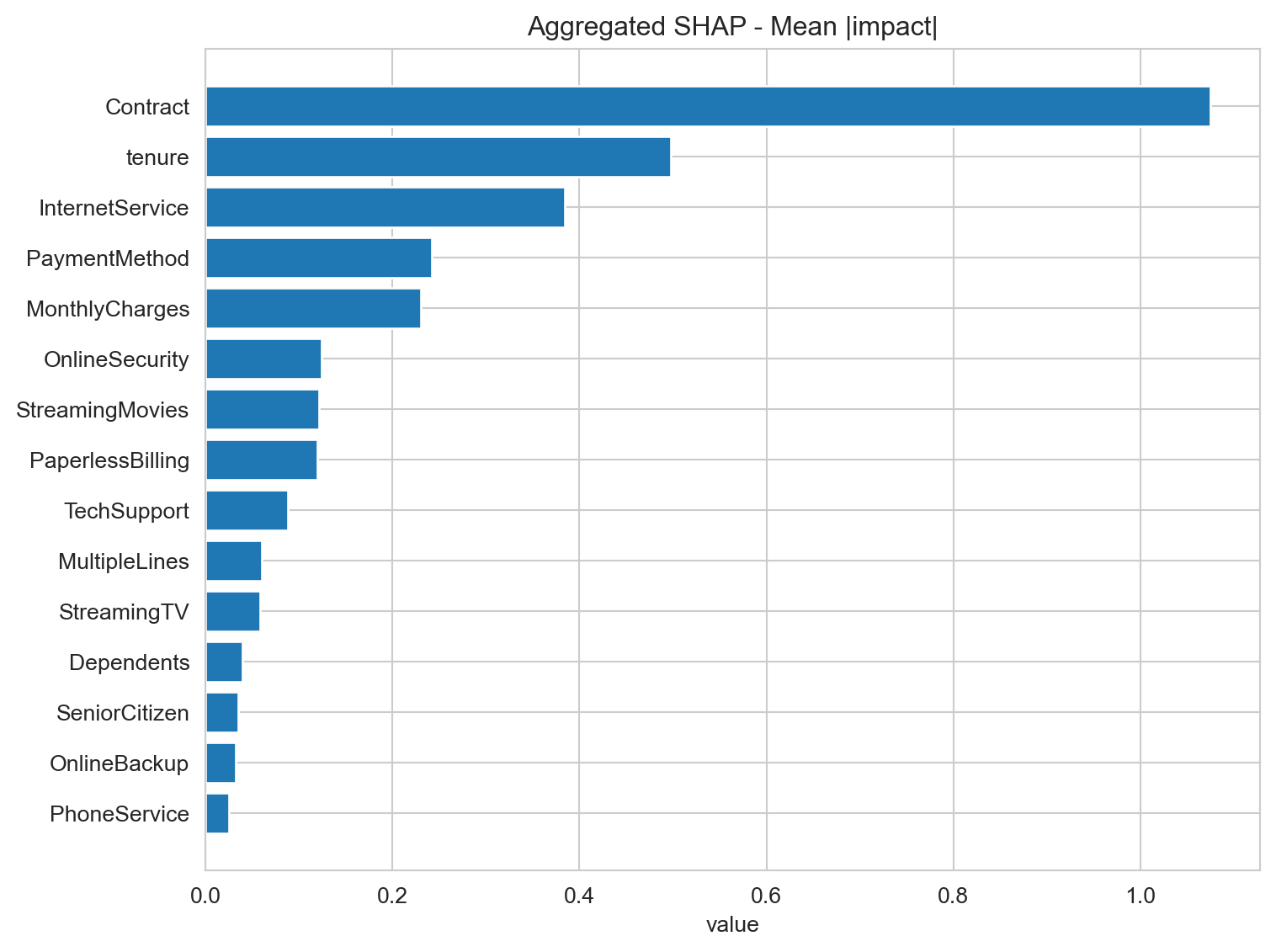
Feature Importance
Feature Importance Analysis seeks to quantify the contribution of each variable (feature) in our dataset to the model’s predictions. In other words, it helps us understand which customer characteristics have the greatest impact on the probability of churn, revealing the “triggers” and “protectors” behind this behavior.
For this analysis, we will employ the SHAP (SHapley Additive exPlanations) methodology. SHAP is an advanced and widely respected technique known for its ability to offer transparent and fair interpretability. Unlike simpler methods, SHAP not only tells us “how important” a feature is, but also:
The Magnitude of the Impact: How much a feature, on average, pushes the churn prediction up or down.
The Direction of the Impact: Whether high or low values of a feature tend to increase or decrease the probability of churn.
Individual Context: How each feature affects the churn prediction for each individual customer, allowing for a detailed understanding.
Why is this analysis vital for the Business?
Understanding the importance and directionality of features is fundamental for:
Strategic Prioritization: Directing marketing, sales, and customer service resources to the areas that truly make a difference in retention.
Developing Focused Actions: Creating retention campaigns, adjusting product/service offerings, or improving aspects of customer service based on concrete evidence.
Identifying Opportunities: Discovering new insights into the profile of customers who churn and those who remain loyal.
By the end of this analysis, we will have a clear view of the main drivers of churn, empowering the business to make more informed and proactive decisions to improve the satisfaction and loyalty of our customers.
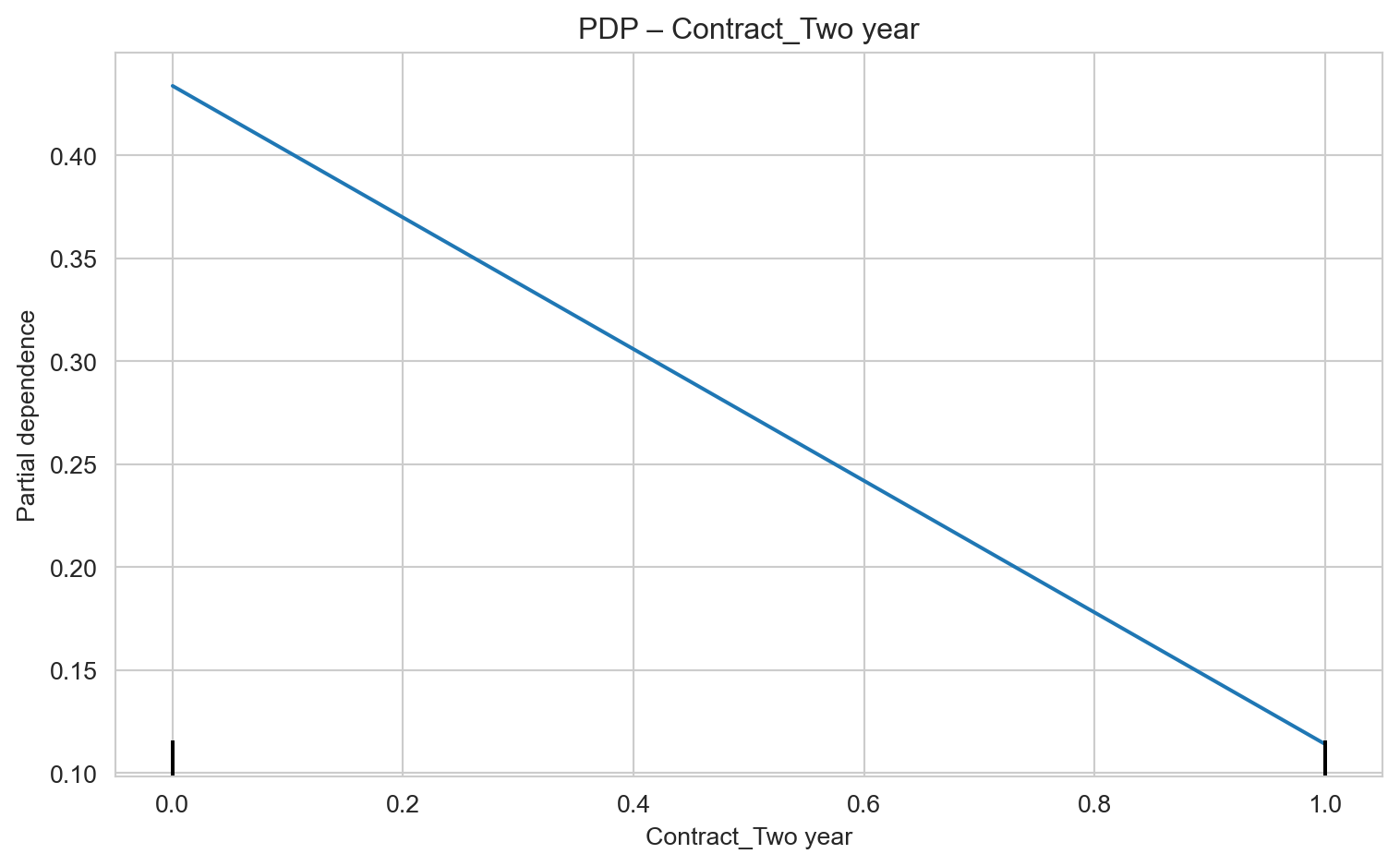
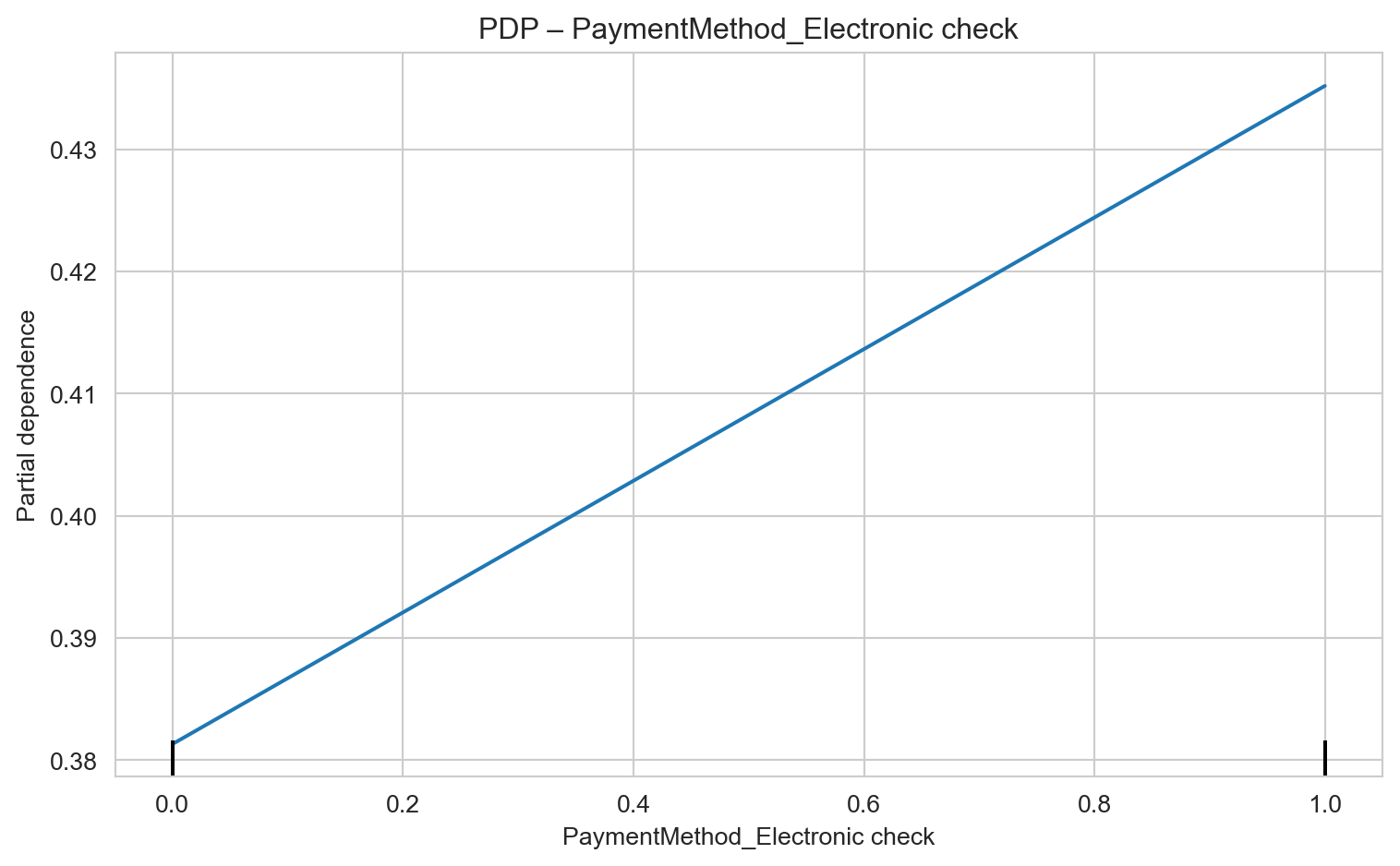
# select top 6 by SHAP global metrictop6 = imp_shap_df["feature"].head(6).tolist()for f in top6: fig = plt.figure(figsize=(6,4)) PartialDependenceDisplay.from_estimator(lgbm, X_test, [f], kind="average") plt.title(f"PDP – {f}") plt.tight_layout() plt.show()
Contract Type – Two-Year Contracts (Contract_Two year): Customers with two-year contracts show a significantly lower risk of churn. Encourage migration to this type of contract through offers and benefits.
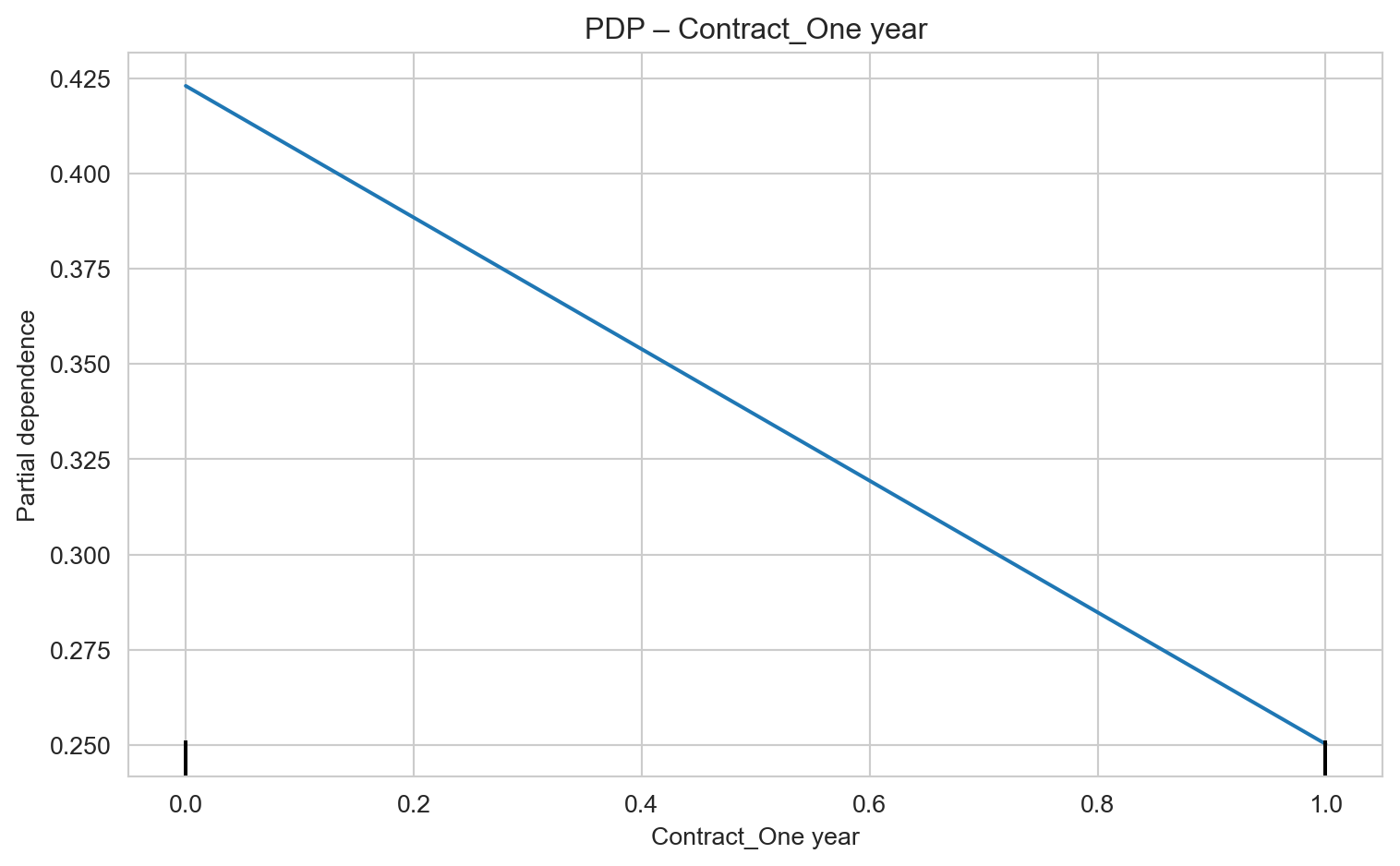
Contract Type – One-Year Contracts (Contract_One year): Customers with one-year contracts also present lower churn risk compared to month-to-month contracts, but higher than two-year contracts. Reinforce the value of renewal and promote the transition to longer-term contracts.
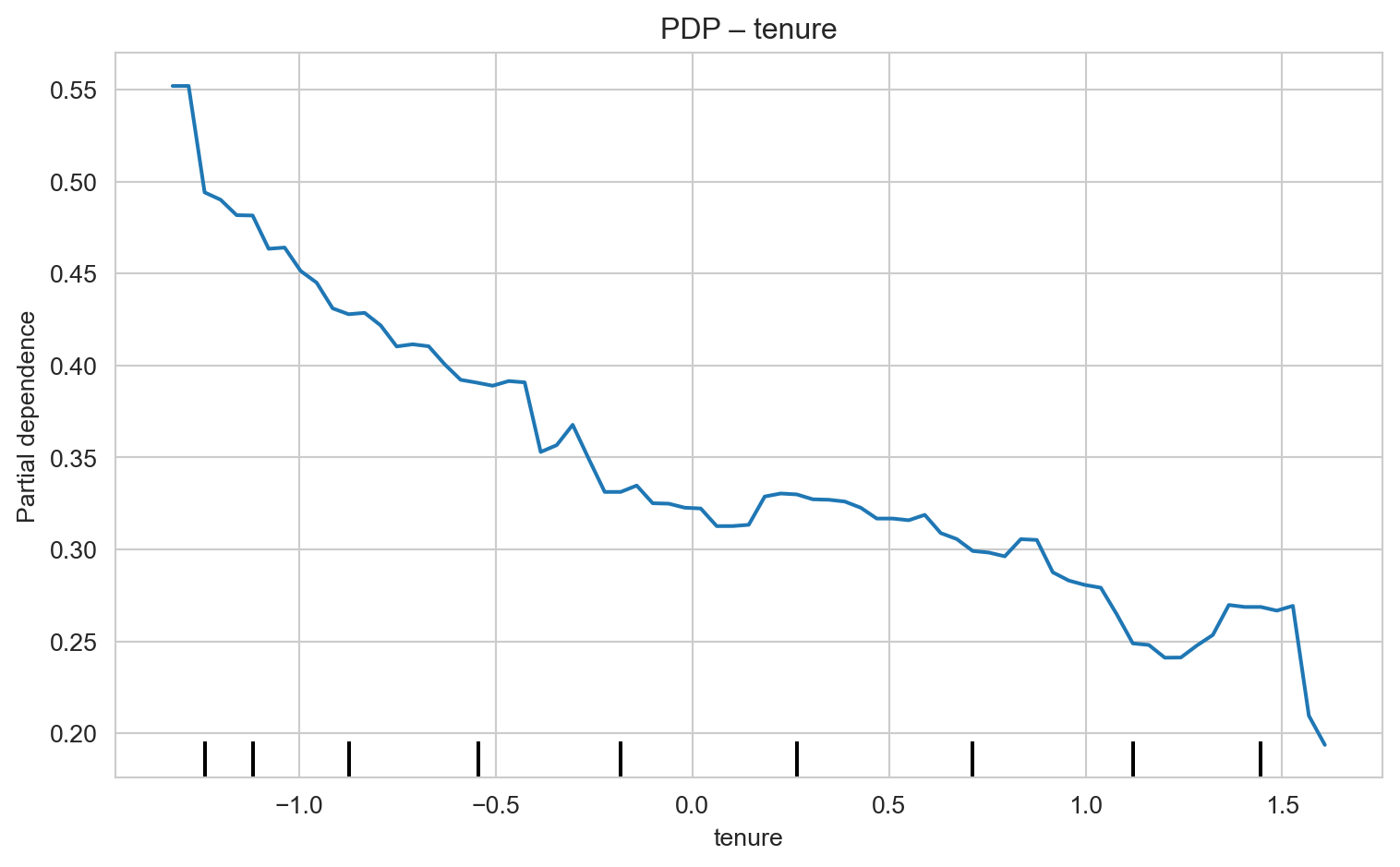
Tenure: Customers with short tenure are at higher risk. Implement robust onboarding programs and proactive follow-up during the first months to ensure satisfaction and early engagement.
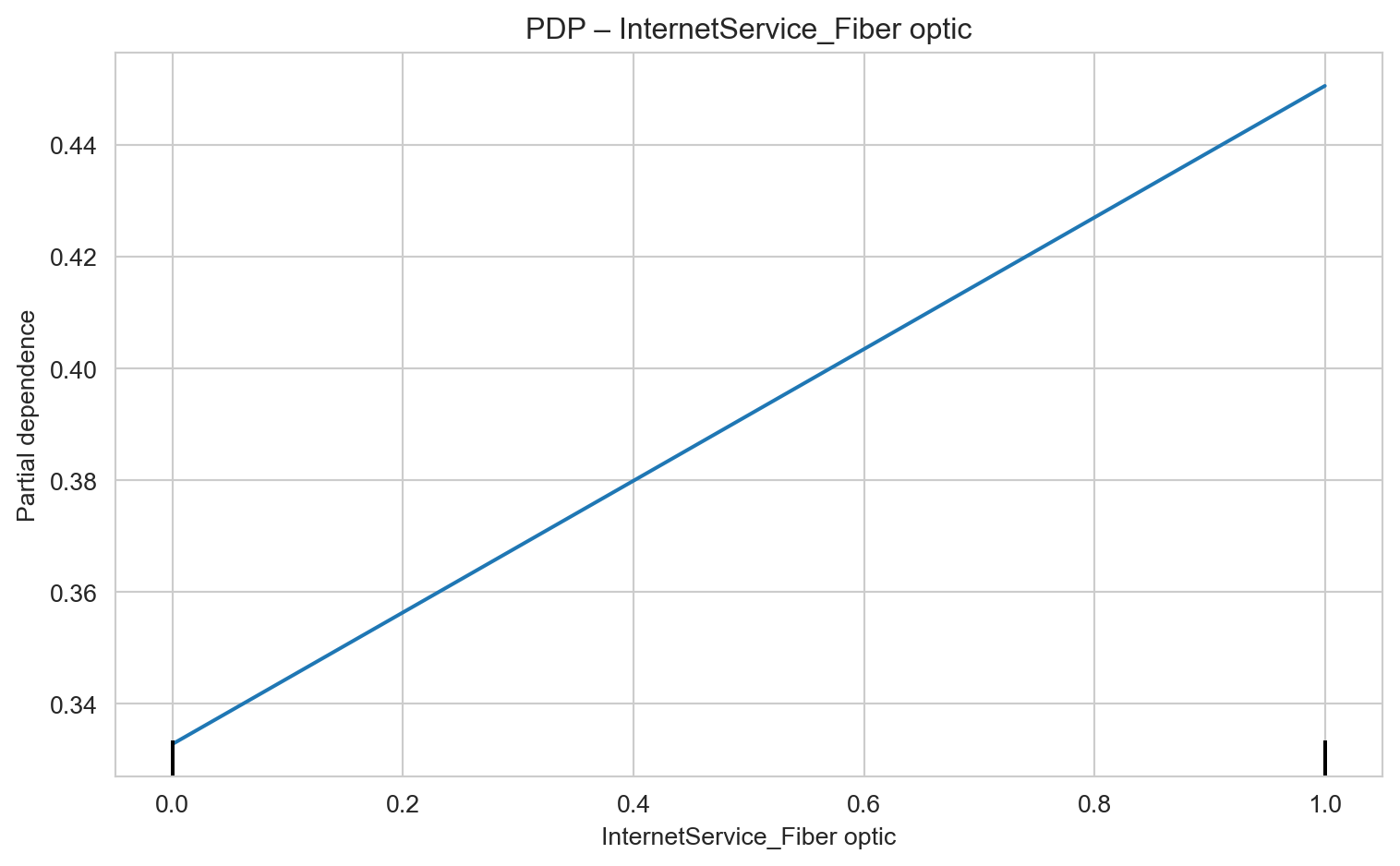
Internet Service – Fiber Optic (InternetService_Fiber optic): The fact that fiber optic customers show higher churn risk is a red flag. Service quality, support, or perceived cost-benefit for fiber users should be urgently investigated. Potential issues may include performance problems or inadequate pricing in this segment.
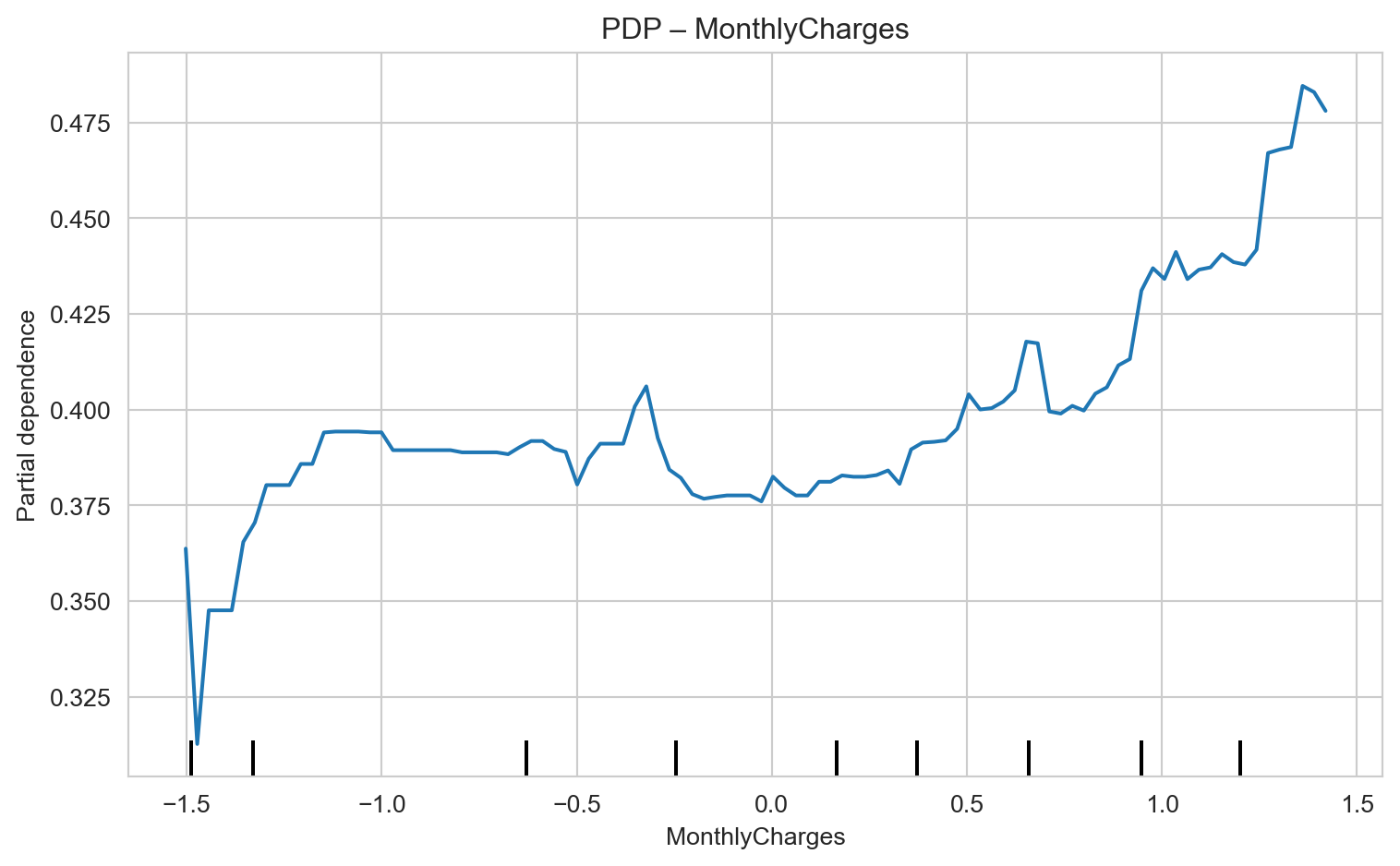
Monthly Charges (MonthlyCharges): Higher monthly charges increase churn risk. Analyze the price ranges where churn is most prevalent. Consider offering bundled packages or renegotiation for customers with high charges, especially when combined with low tenure.
Payment Method – Electronic Check (PaymentMethod_Electronic check): Customers using electronic checks are at high risk. This may indicate a segment with lower loyalty, financial difficulties, or dissatisfaction. Consider incentives to switch to other payment methods or establish closer monitoring for these customers.
Online Security (OnlineSecurity): Not having online security services increases churn risk. Promote the importance and benefits of online security offerings.
Streaming Services (StreamingMovies, StreamingTV): Having streaming services may increase churn risk. This is counterintuitive and may suggest that these services are not adding enough value to retain customers, or that customers seeking such services tend to have a profile more prone to exploring alternatives.
Deploy
Check this model in production by running churn predictions: